Feature Transform
Introduction
In lecture 3, we’ve discussed some feature distributions which make linear classifier hard to deal with. Feature transform is a solution to this problem, which involves in change of variables
For example, if the feature distributions are in circle, then we can apply change of variables to make linear classifier works
Different Ways of Feature Transform in Computer Vision
D-DL4CV-Lec05a-Feature_Transform
Neural Network
Introduction (Use Two-Layer Neural Network as Example)
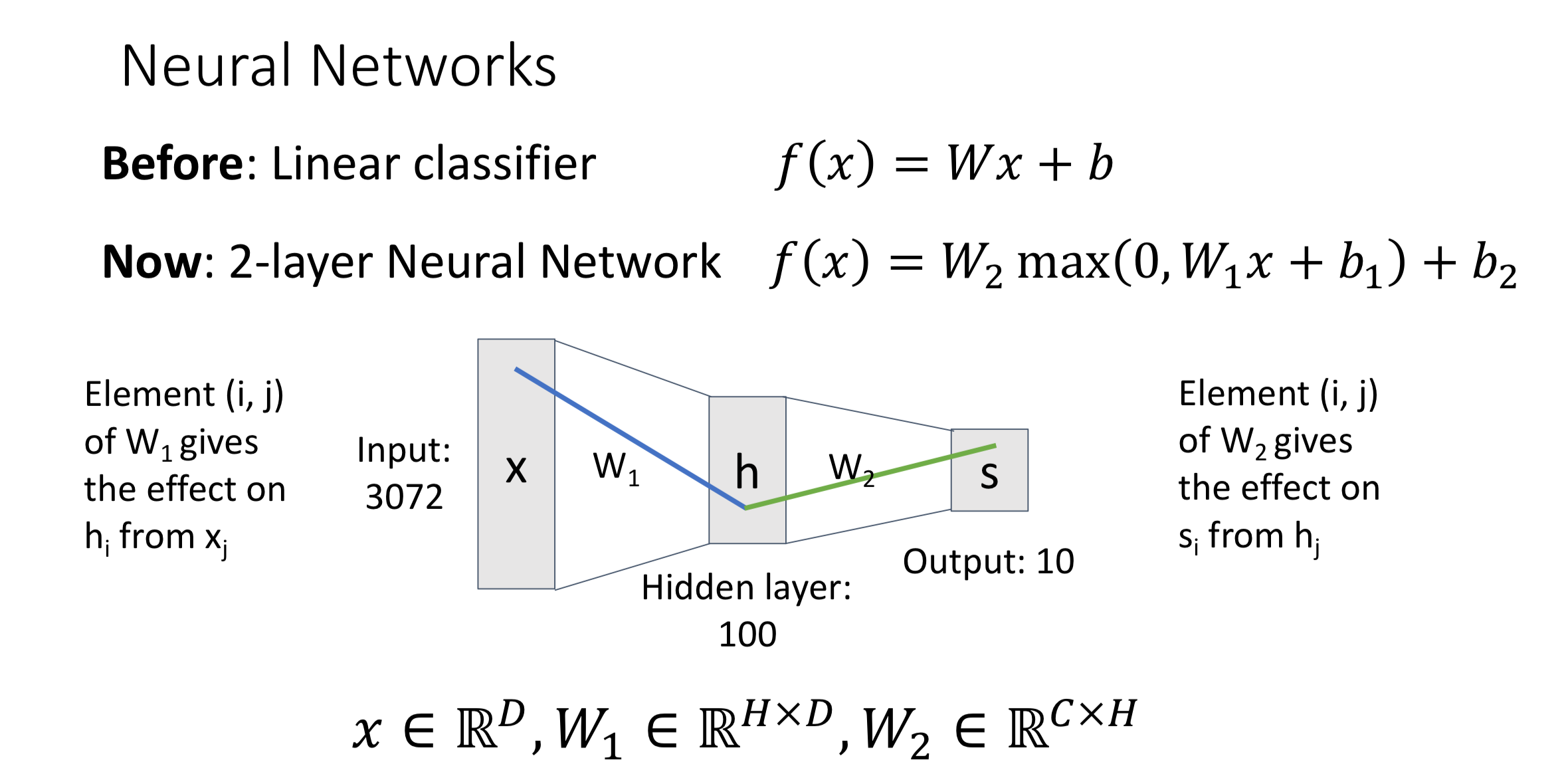 Input Layer → Hidden Layer:
Input Layer → Hidden Layer:
Hidden Layer Neuron:
Hidden Layer → Output Layer:
In convention people often ignore the bias term when writing it. However, we should keep in mind that the bias term still exists
Concepts
Fully-Connected Neural Network
If every neuron in the second layer is a linear combination of all the neurons in the first layer, then we said the neural network to be “fully-connected”
also can be called as "Multi-Layer Perceptron" (MLP)
Depth
Depth is the number of layer with trainable parameters (thus exclude input layer) Another way to get the depth of the layer is by counting the number of weight matrices
Width
The width of a layer is the number of neurons in the layer
Distributed Representation
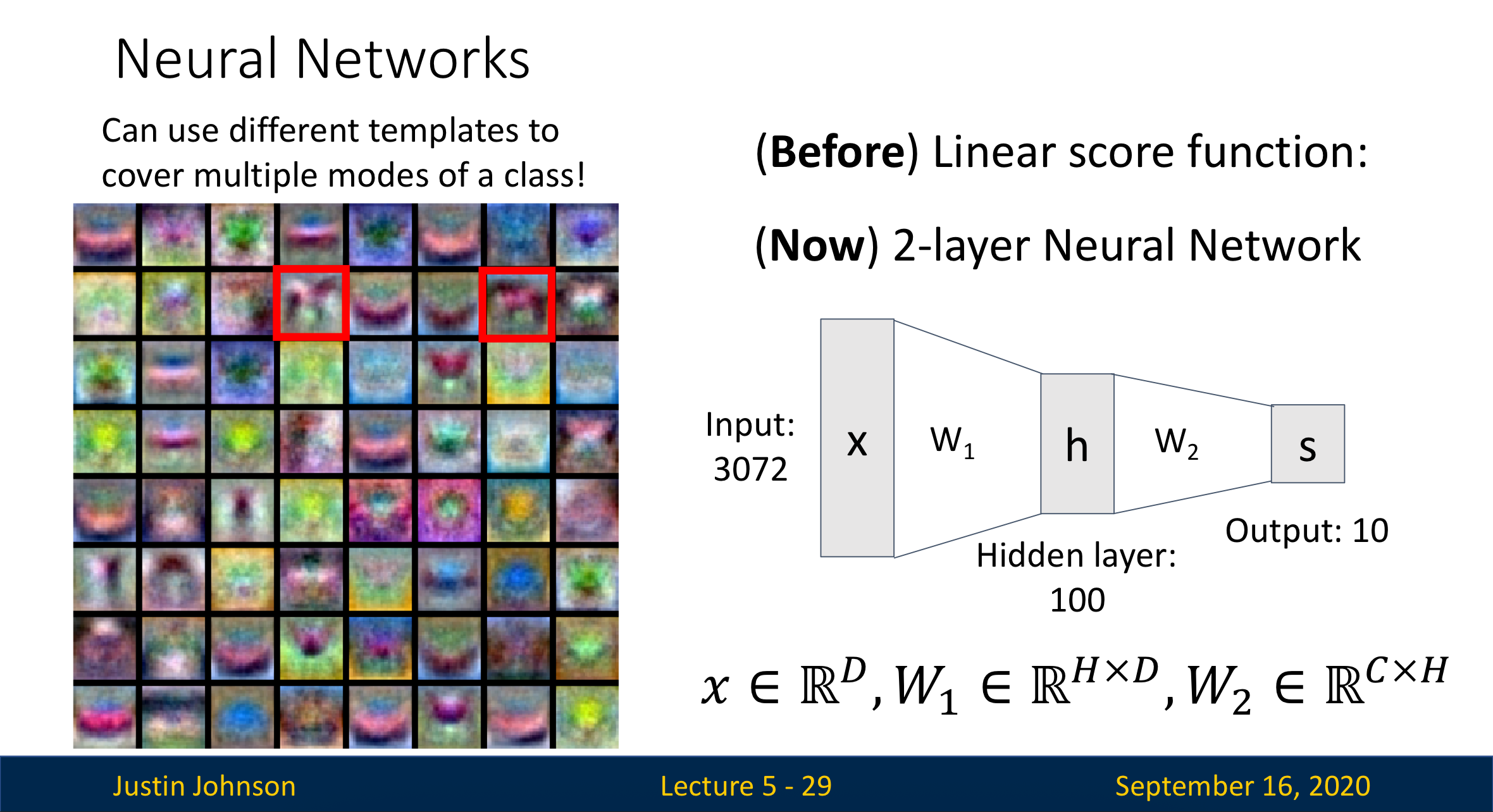
When we use linear classifier, we notice that only one template per label can’t cover every possible appearance of the label
The concept of “distributed representation” is using multiple templates per label to cover every possible appearance of the label. For example, the horse facing left and the horse facing right can be separated into two templates.
These templates are stored inside the hidden layer. When we head from the hidden layer to the output layer, each of the template will contribute to the final decision
Like seen in the picture, some templates in hidden layer aren't interpretable
Activation Function
Introduction
Activation function is a key component to make neural networks work as we expect It decides how much strength should we “recommend” this neuron (template) to the next layer
Some Activation Functions
| Name | Function |
|---|---|
| ReLU | |
| Sigmoid | |
| … | … |
Most of the time ReLU is a good default choice for most of the problem
Why is activation function so important?
Use the two-layer neural network as example, its process can be written as:
If we get rid of the activation function (ReLU), then we’ll left with:
Let , then , which makes the neural network again a linear classifier.
Hence, we can conclude that it is the activation function that makes neural networks different from linear classifier
Space Warping
Universal Approximation
D-DL4CV-Lec05c-Universal_Approximation