Concept Explanation
Assumption
We use images in CIFAR10 ( RGB pixel) as example:
Let the task be:
- A training set of images
- Each image has pixels
- The output can be one of the labels
For each image:
- be vector representation of the image
- be the answer class for this image
Linear Classifier
For the assumption above, its linear classifier is defined as:
where
- is the weight of the function, which is a matrix. Each row of a weight will calculate the score for a label
- is the bias of the function, which is a matrix
Output
We’ll get a matrix as output, where each entry correspond to how confident the linear classifier thinks the input image matches the class
Different Viewpoints
Algebraic Viewpoint

1. Bias Trick
If we view the linear classifier pure algebra, we can observe is a matrix and is a matrix.
For calculation efficiency, we can
- Make as an extra column to , which creates an augmented matrix
- Add constant as the entry in , making a matrix
Thus, the linear classifier becomes
The significance of doing this is increasing the calculation speed by using the concept " parallel computing"
2. Prediction are Linear
If the linear classifier is
then
Making each RGB value half in the original image will make the fades but preserve the original color
From the human perspective, the two images are almost the same, but linear classifier gives only half of the score, this may affects the function of loss function
Visual Viewpoint

In visual viewpoint, we don’t stretch the input into vector (). Instead, we maintain its shape (). Now, we calculate score to each label separately, we’ll then have weights in the shape
We call the weights in this shape a template, it represent how linear classifier thinks the “average image” of this label looks like
Looking at the slide above, you can see the horse picture has two head, since in the dataset there are horse facing left and horse facing right
Thus one template per label can’t represent all kinds of images in this label, we’ll solve this problem using neural network in the neural network lectures
Geometric Viewpoint
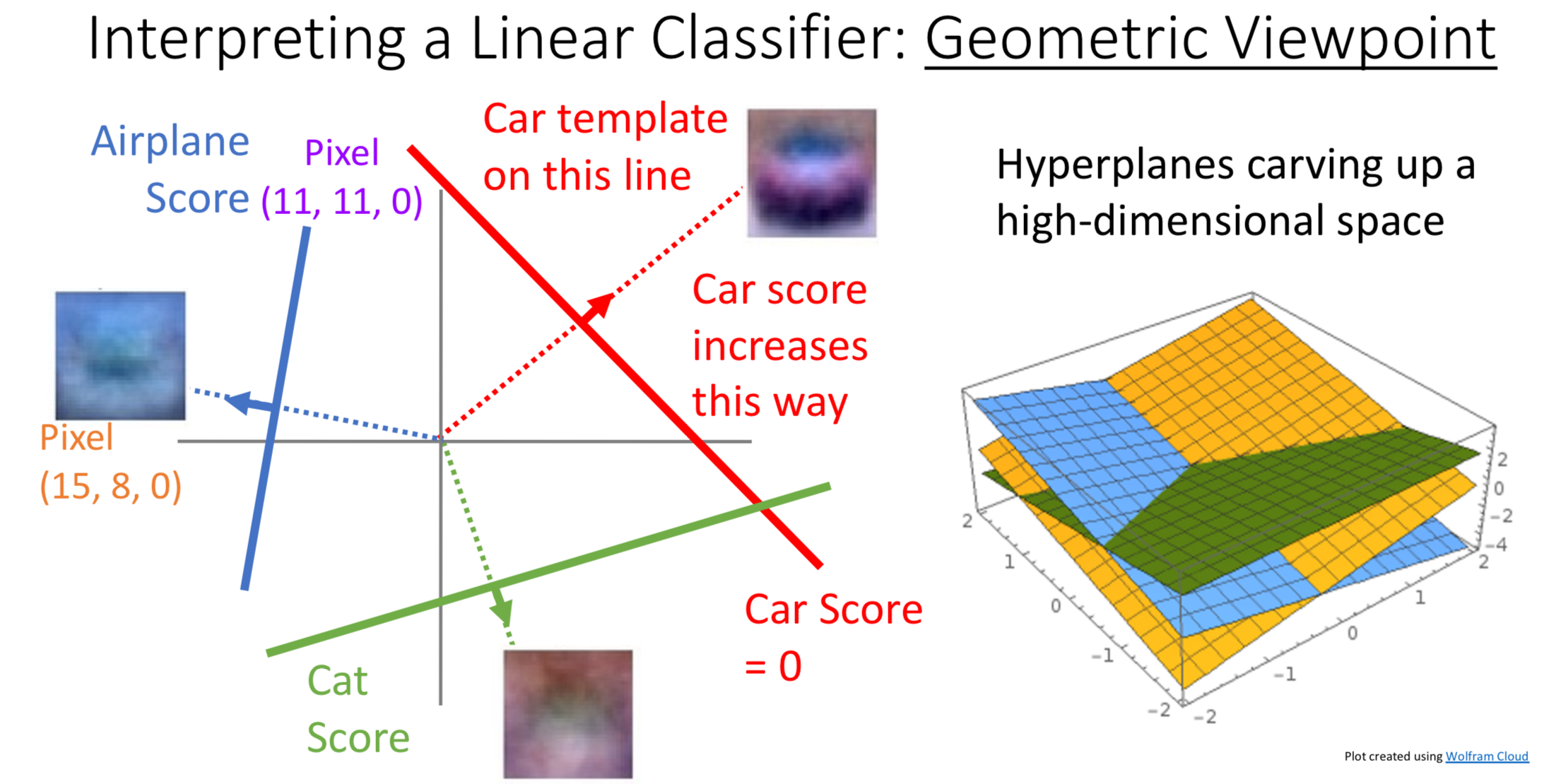
1. Thinking of Input Images as Points in Space
In the geometric viewpoint, we treat each feature of the image (such as a pixel’s RGB value) as a dimension in space. Every image corresponds to a single point in this multi-dimensional space. Images that share similar characteristics will appear as points that are positioned close to each other in this mathematical space.
2. Linear Classifier as a Plane in Space
The linear classifier can be thought of as a plane defined by the equation in this space. When the plane moves in the direction of its normal vector, the score increases, and vice versa. This geometric relationship allows us to understand how the classifier assigns different scores to different points in the feature space.
3. Making Decisions
By using mathematical methods, we can calculate the “distance” from the point that represents the image to the linear classifier plane (defined by ). This distance tells us how close the image is to each possible class label.
With the distance values between the image and every class label, we can determine which class the image should be classified into by selecting the class with the smallest distance or highest score.
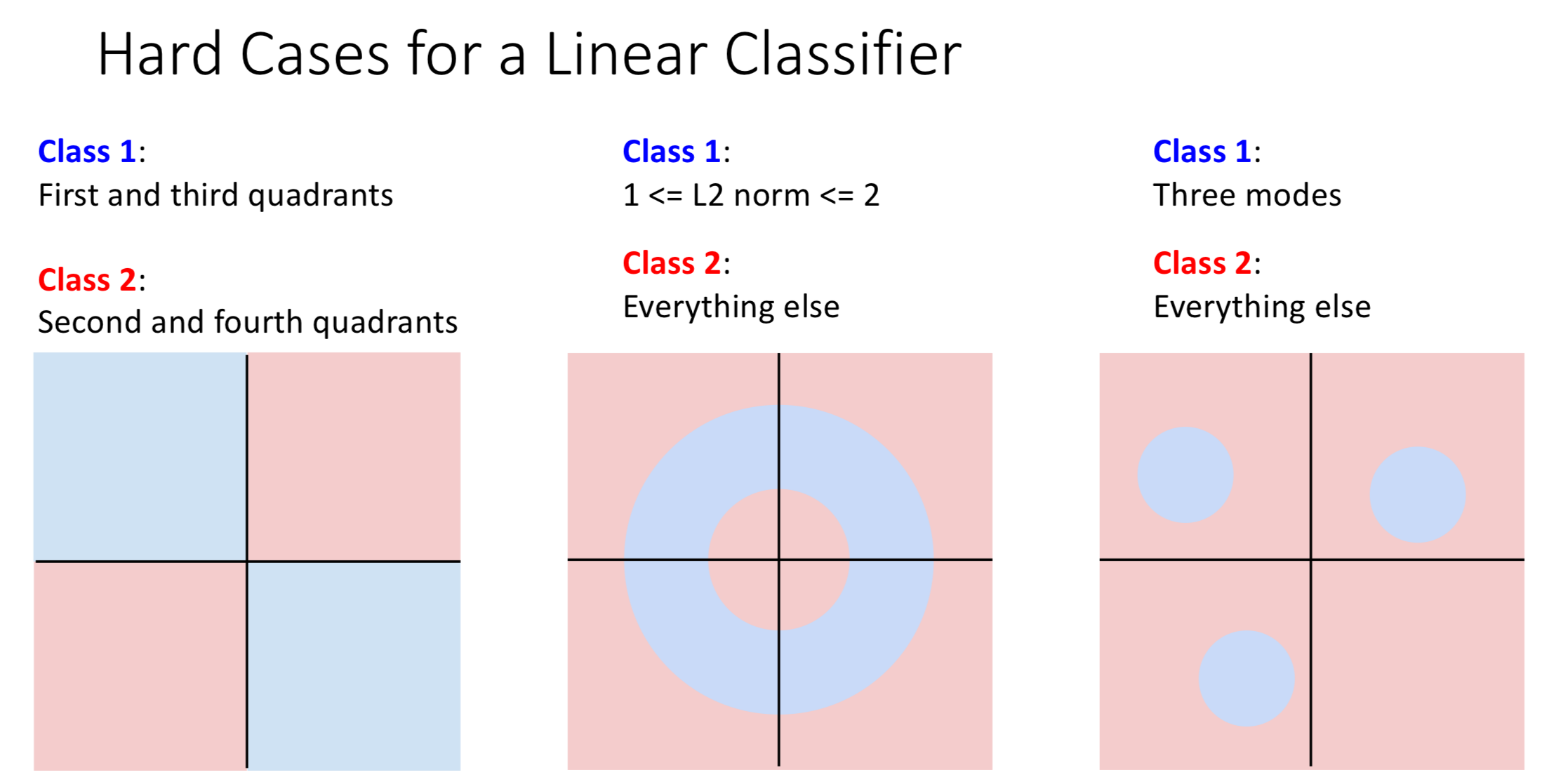
Hard Cases for Linear Classifier
The three cases in the picture below show the limitation to linear classifier. These cases use two dimension to explain the idea, but in reality the number of dimension will be much larger
Explanation: For these three cases, we can not use a straight line (linear classifier) to divide the region separating different classes