Universal Approximation
Theorem
A neural network with one hidden layer containing finite neurons can approximate any continuous function in any precision
Explanation
Output of a neuron in the hidden layer is a shifted, scaled ReLU

- The image on the right represent a neuron in hidden layer
4 of these properly shifted ReLUs create a bump function
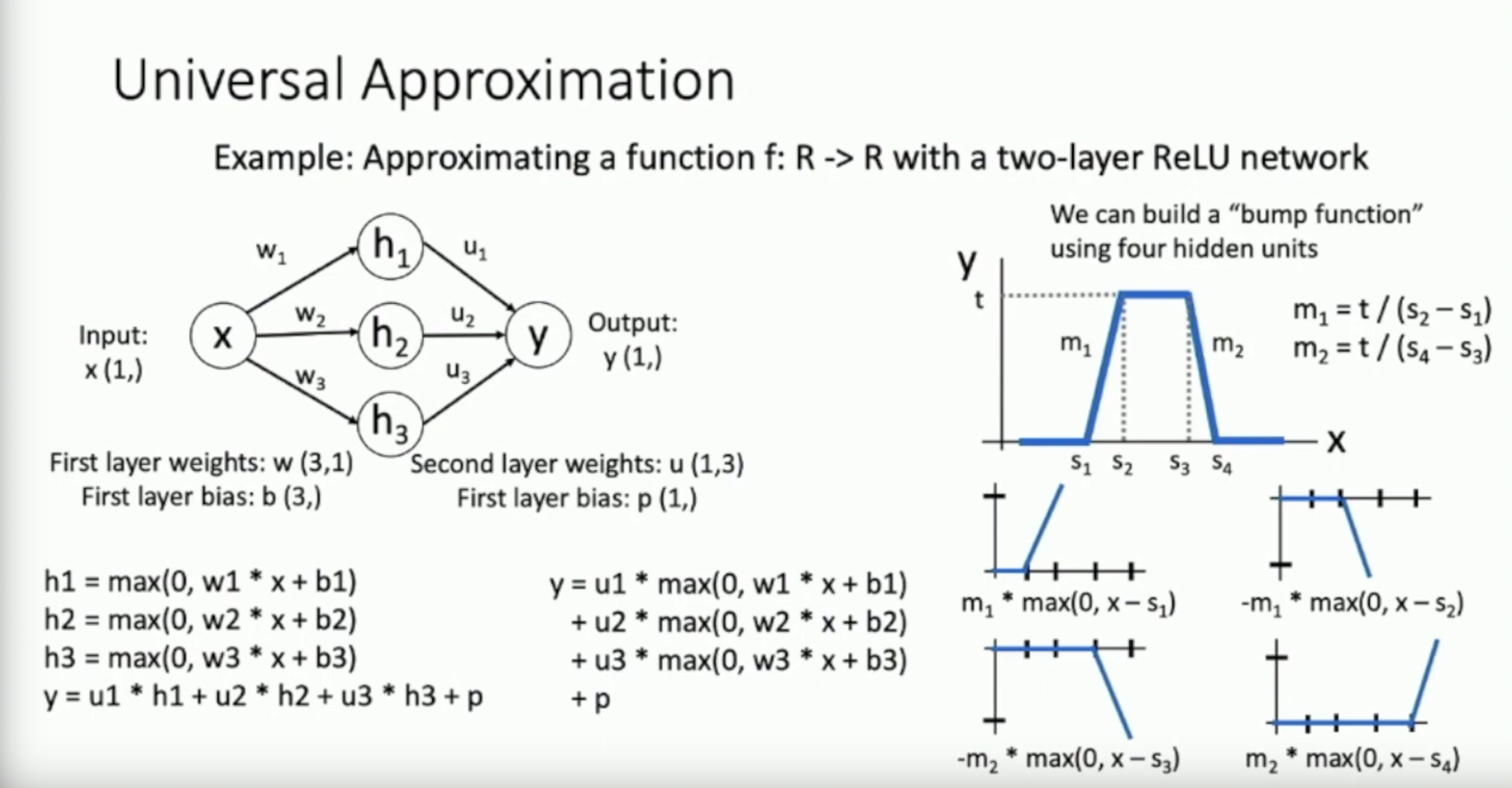
- Two neuron can represent from flat at to flat at
- The other two neuron can represent going down from to stay flat at
With many of these bump functions, we can approximate any continuous function

- With many bumps we’ve created in the last step, we can simulate any continuous function
Statement
What Universal Approximation Tells Us:
- Neural networks can represent any function
What Universal Approximation Don’t Tells Us:
- Whether the optimization process can really learn any function
- How much data we need to learn a function