RAID
Motivation
一台電腦現在可以有多個 storage device 了,而多個 storage device 自然而然帶給我們一些想法
- 很多硬碟那壞掉一個的機率是不是變大了?那該怎麼避免資料遺失
- 既然有多個硬碟,那是不是可以對多個硬碟做 parallelism 或 load balancing 來提升 request 處理效率
Improvement of Reliability via Redundancy
Problem
硬碟越多,「至少壞一顆」的機率就越高。假設我們有 100 顆硬碟組成的陣列,那麼平均每 41 天就會壞一顆,也就是如果沒有任何保護措施,資料幾乎必定遺失
Resolution: Redundancy
解決方法就是主動透過各種方式利用儲存冗餘的資訊來保證你在一定數量的同時損壞的情況下仍能通過各種方法將這些資料重新找回來
Improvement in Performance via Parallelism
Mirroring
既然我們鏡像了兩份一樣的資料,那 read request 就可以送往任意一處,讓 throughput 直接快了一倍,然而單次傳輸速率其實沒變
Data Striping
如果目標是提升「每次傳輸的速度」而不是 request 處理速度,就需要 striping 了
它的想法是把資料分散在多顆硬碟上,讓多顆硬碟同時傳輸一份資料的不同部分
第一種方法叫做 bit-level striping:把每個 byte 的 8 個 bit 分散到 8 顆硬碟。讀一個 byte 八顆硬碟同時出力,理論上可以達到八倍效率
但實際上常用的是 block-level striping,也就是把不同 block 分配到不同硬碟
Tradeoff
Redundancy 提供了 reliability 但是很貴;Striping 提供了高 data-transfer rate 但不會提升 reliability,RAID 包含了多種策略每種策略都側重不同方面
RAID Scheme
Raid 0
RAID 1
RAID 4
RAID 5
RAID 6
RAID 1+0 vs. RAID 0+1
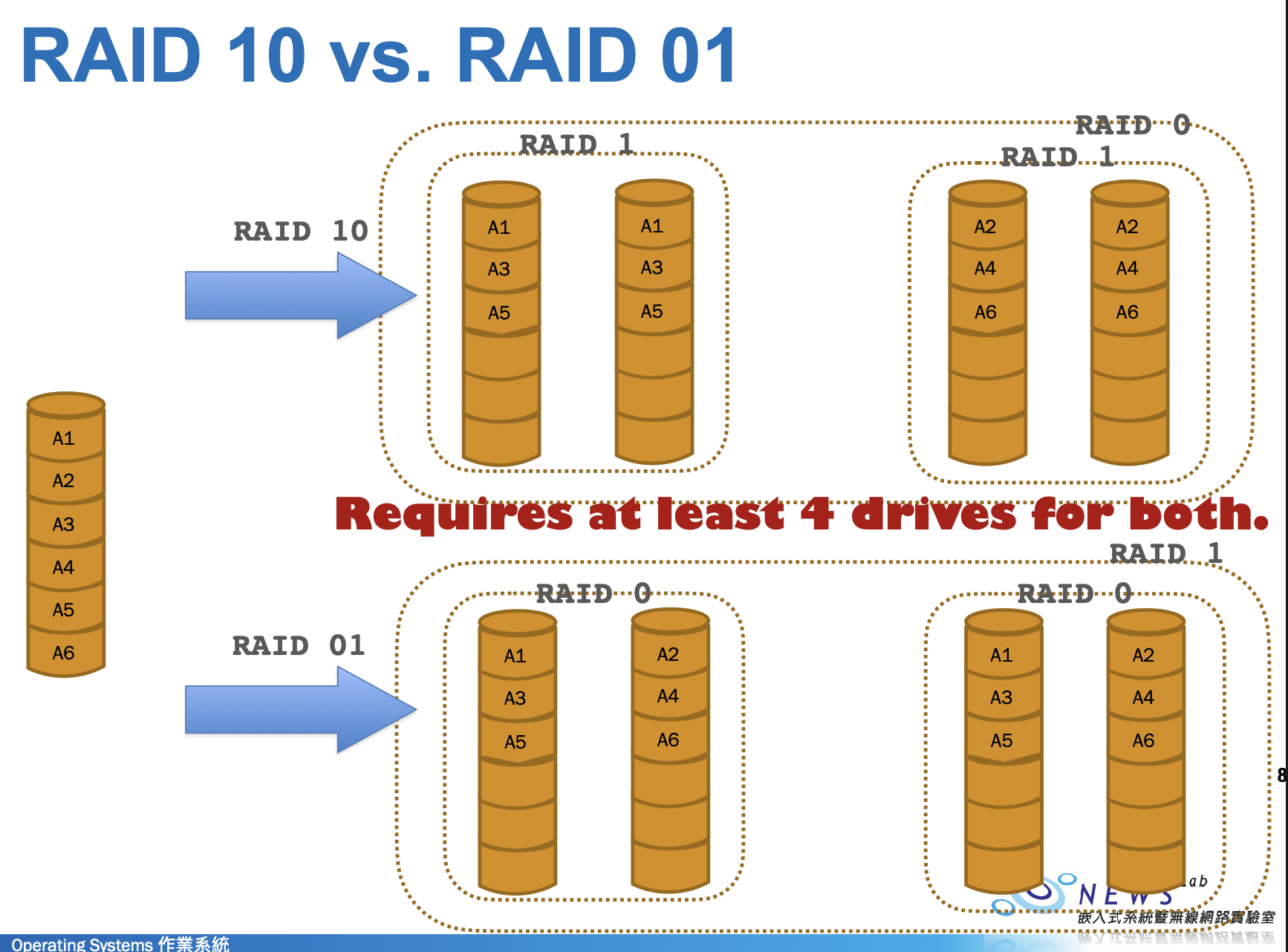
RAID 1+0
先將硬碟兩兩配對做組成一個個 RAID 1,然後將一份資料對每對硬碟做 block-level striping 將對與對之間組成 RAID 0
寫入資料(8 個 blocks)
│
╔═══════════╧═══════════╗
║ RAID 0 Striping ║
╚═══════════╤═══════════╝
┌────────┴────────┐
▼ ▼
┌─────────┐ ┌─────────┐
│ RAID 1 │ │ RAID 1 │
│ Pair 1 │ │ Pair 2 │
└──┬───┬──┘ └──┬───┬──┘
▼ ▼ ▼ ▼
Disk Disk Disk Disk
A B C D
─── ─── ─── ───
B1 B1 B2 B2
B3 B3 B4 B4
B5 B5 B6 B6
B7 B7 B8 B8
Pair 1 (A=B) 存奇數 blocks,Pair 2 (C=D) 存偶數 blocks
容錯:每對中壞掉任一顆硬碟都不影響資料
RAID 0+1
先將硬碟分成一半,互為對方的 mirror(也就是做 RAID 1),然後再將資料在兩邊做 stripe(也就是做 RAID 0)
寫入資料(8 個 blocks)
│
╔═══════════╧═══════════╗
║ RAID 1 Mirror ║
╚═══════════╤═══════════╝
┌────────┴────────┐
▼ ▼
┌─────────┐ ┌─────────┐
│ RAID 0 │ │ RAID 0 │
│ Set 1 │ │ Set 2 │
│ (原始) │ │ (備份) │
└──┬───┬──┘ └──┬───┬──┘
▼ ▼ ▼ ▼
Disk Disk Disk Disk
A B C D
─── ─── ─── ───
B1 B2 B1 B2
B3 B4 B3 B4
B5 B6 B5 B6
B7 B8 B7 B8
Set 1 (A+B) 與 Set 2 (C+D) 互為完整鏡像
容錯:Set 1 中只要有任一顆硬碟壞掉,整個 stripe set (RAID 0) 即失效
Conclusion
RAID 1+0 比 RAID 0+1 容錯率大
Problem with RAID
Limitation with RAID
RAID 只是設計給實體硬碟故障的問題的策略,還有很多問題他處理不了,如:
- file system 中的指標如果指錯位置
- 資料寫到一半斷線(一半資料對一半資料錯)
- RAID controller 本身壞掉
上面這三例都是 RAID 本身處理不了的
Flexibility
如果我們有一堆硬碟然後規劃成多個 RAID sets,如果某個 RAID set 的空間不夠用了,而另一個則剩很多空間,我們想要重新分配空間,但對 RAID 來說這必須做備份還有一大堆很麻煩的東東才能做到
Solution
ZFS 被發明了,在 chapter 14 才會說