Motivation
As we’ve discussed earlier (note), RNN or RCN is not parallelizable, thus can’t make the most of the GPU
Our solution is self-attention, and now we want to bring it to video classification
Self-Attention for Video Classification
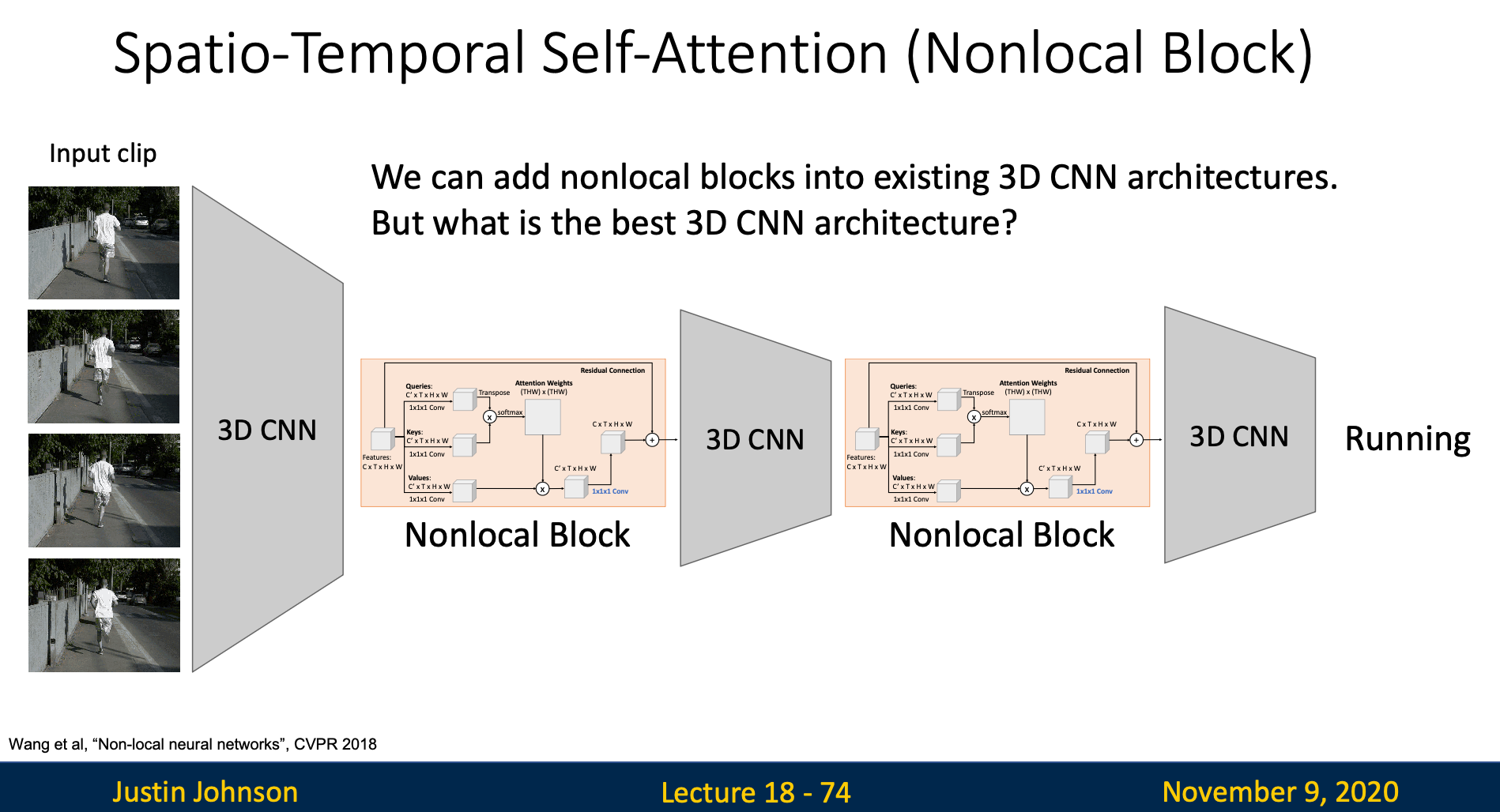
Non-Local Block
Non-local block means that every output element of this block depends on every input elements
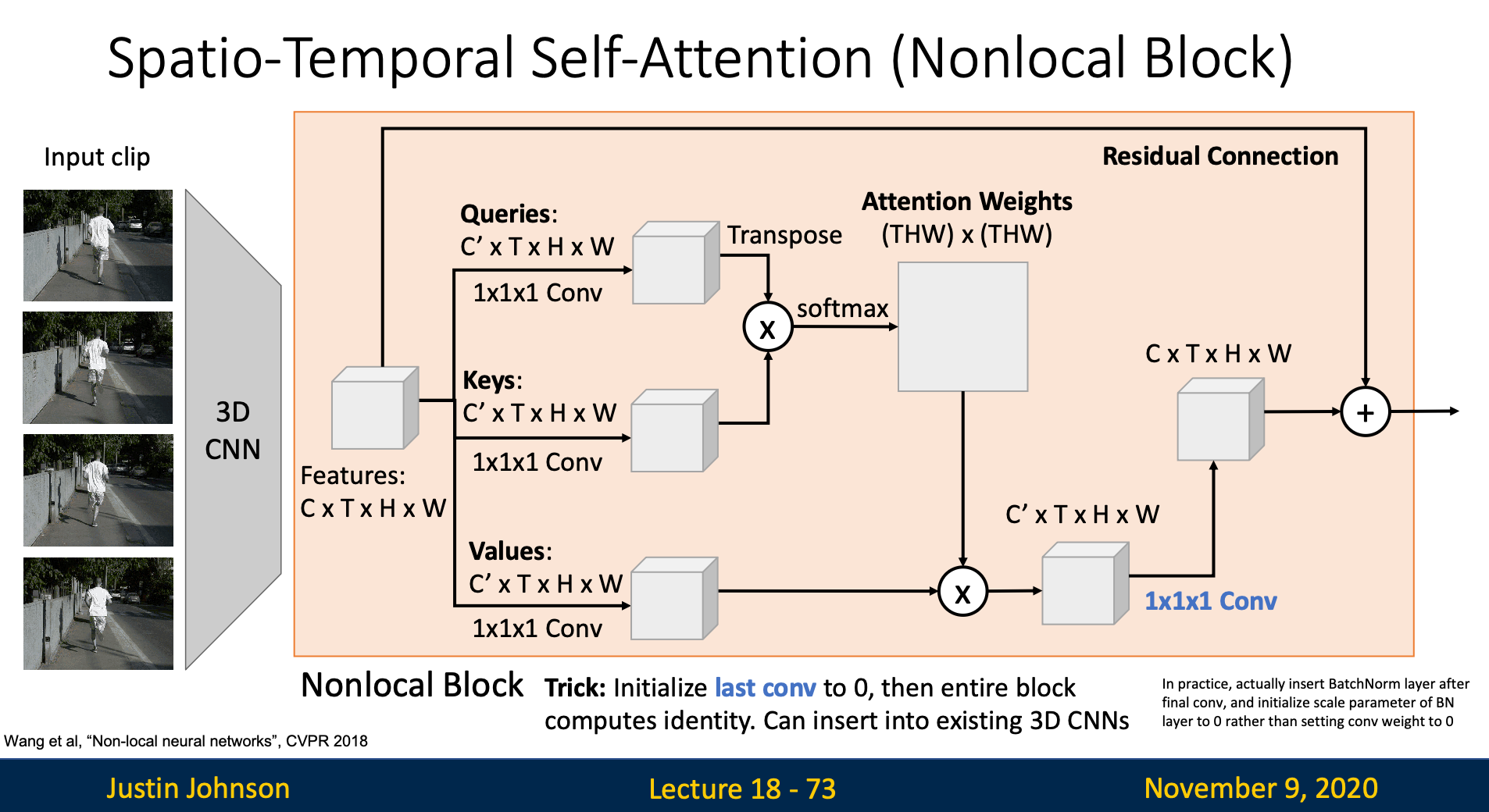
Self-Attention
- Recall: Self Attention It is almost entirely the same as original self-attention layer
- We compute queries, keys, and values with input feature map
- Use queries and keys to compute attention weight, which tell us how hard each output element depends on every input elements
- Next, we multiply attention weight with values to get output vector
- Since we want the input and output have the same dimensions, we’ll use convolution to resize the channel
Insert Self-Attention Layer into 3D CNN
If we initialize the last convolution to zero, then the entire block computes identity in default. Hence, we can insert self-attention layer between layers in 3D CNN