Recurrent Convolutional Networks (RCN)
Problem
We want to process long videos, but temporal dimension will make it computational expensive if we use models we introduce before
Two Approaches
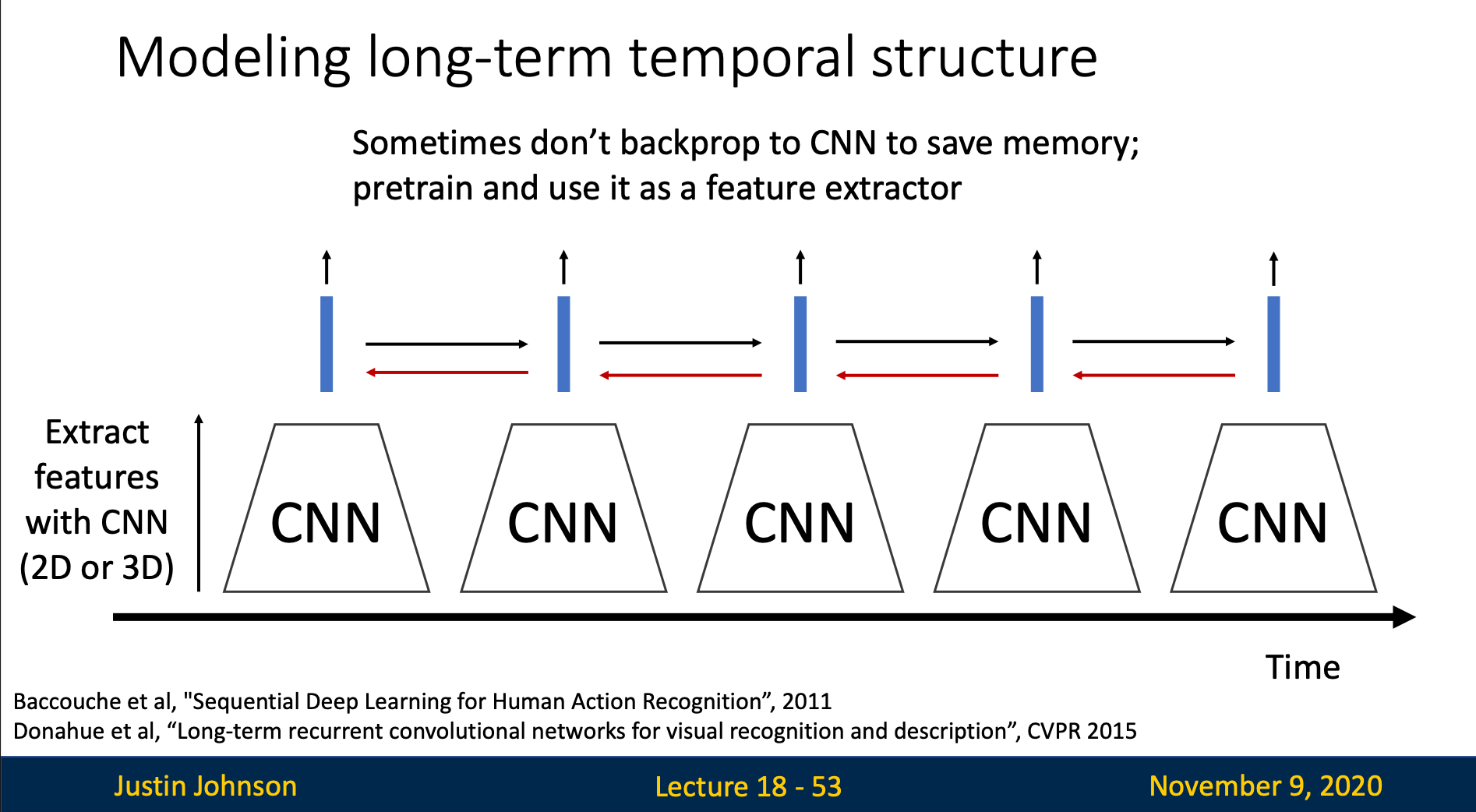
CNN + RNN Pipeline
Video → Short Clips → CNN Features → RNN → Output
- Separate spatial and temporal processing
- CNN compresses spatial info into 1D vectors
- RNN processes temporal sequence
Multi-Layer RCN
- Key Idea: Integrate convolutions directly into RNN structure
- Maintains 2D feature maps throughout processing
Multi-Layer RCN Architecture
Two Recurrent Connections
Each layer depends on:
- Temporal: (same layer, previous time)
- Hierarchical: (previous layer, same time)
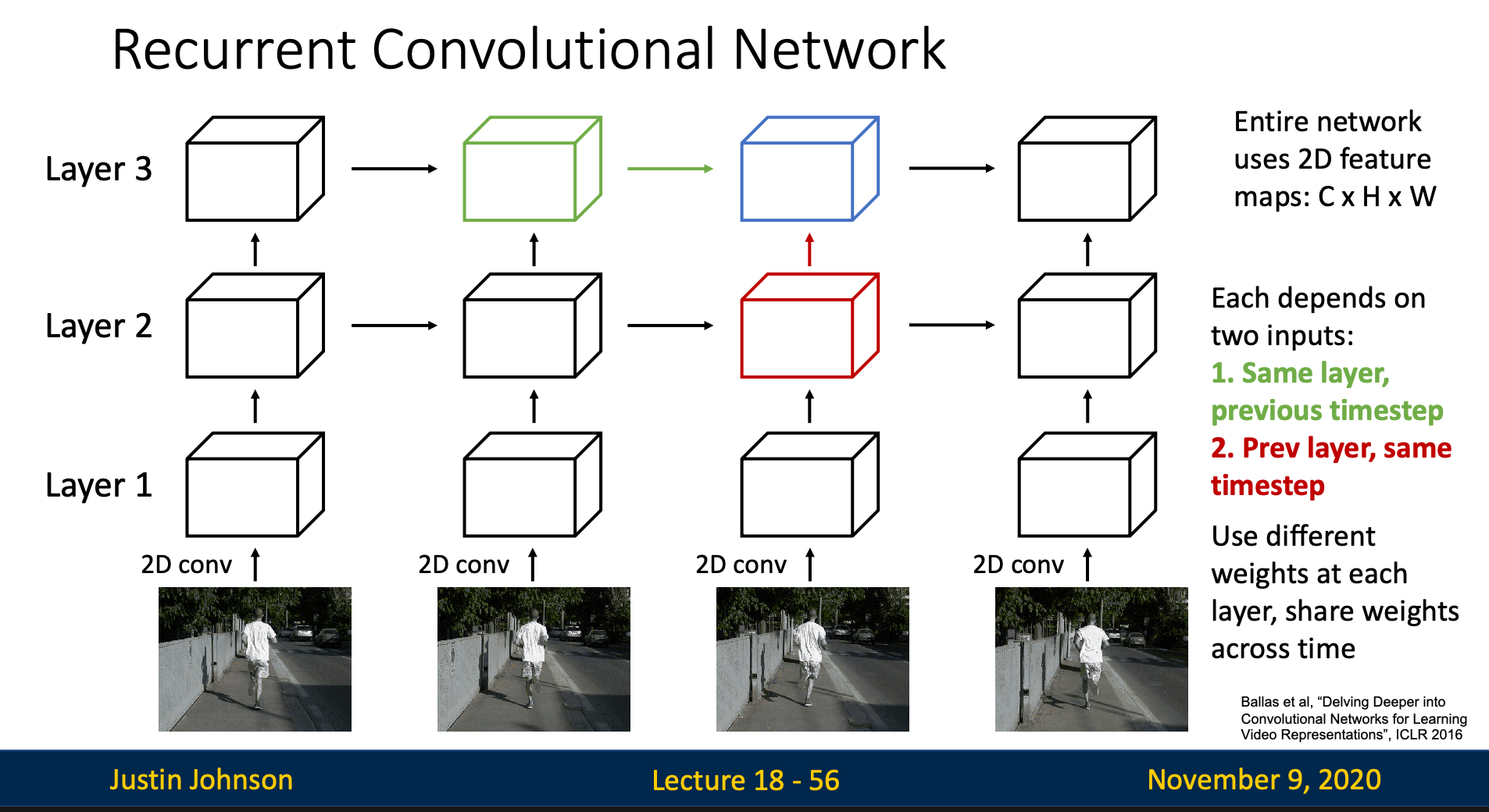
Key Difference
- RNN: Uses weight matrices on 1D vectors
- RCN: Uses convolutions on 2D feature maps
Comparison
| CNN + RNN | Multi-Layer RCN | |
|---|---|---|
| Processing | Sequential | Integrated |
| Spatial Info | 1D compressed | 2D preserved |
| Architecture | Two networks | Single network |
Result: RCN treats video as unified spatial-temporal data rather than “images + time”