Introduction
Data preprocessing is discussing some operations that we can act on the input before passing it into the network
Methods
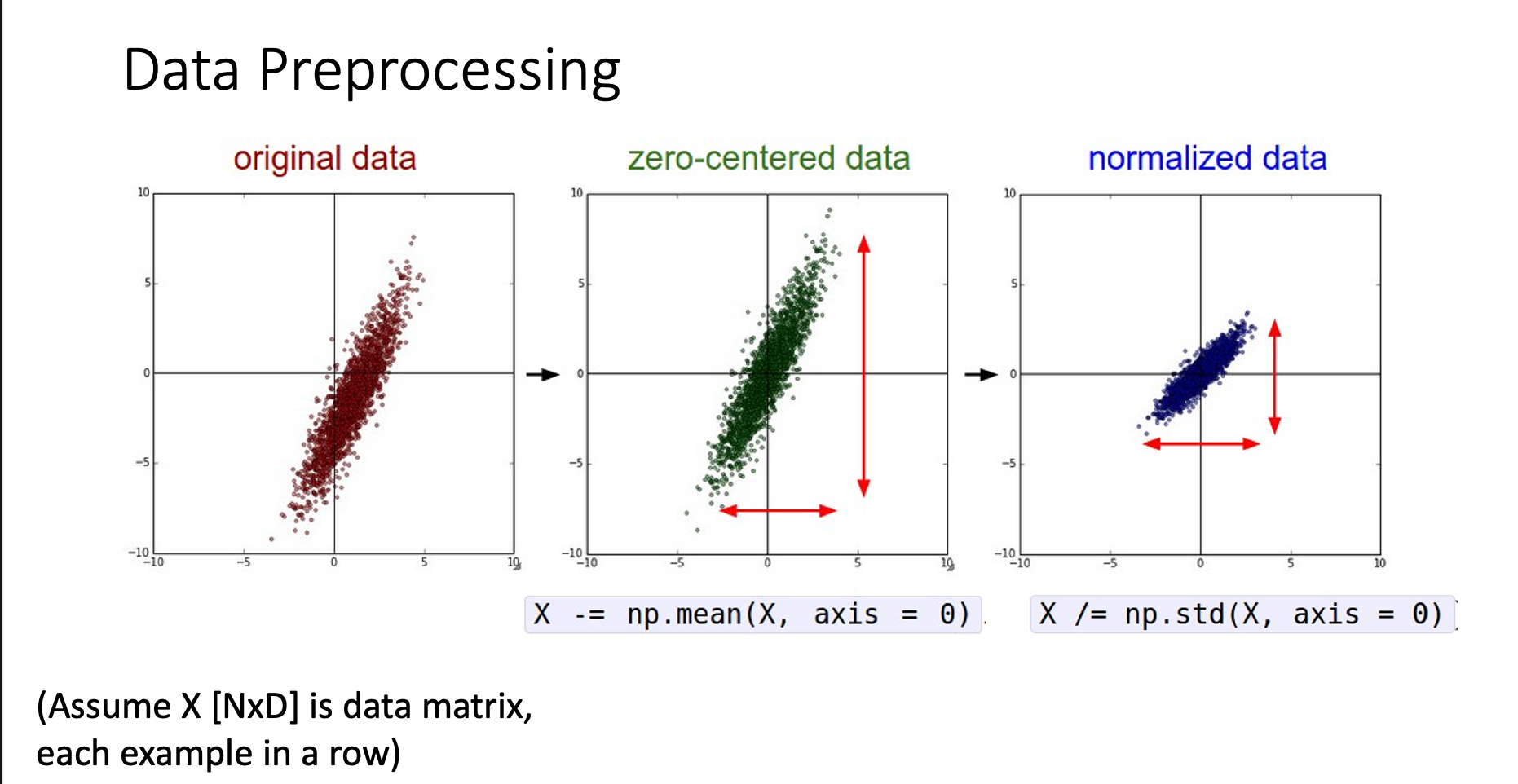
Subtract by Mean to get Zero-Centered Data
Recall when we are discussing activation function, we’ve mentioned . Now imagine when input is always positive, what will this cause?
The answer is that for most of the activation functions we’ve discussed, this will cause the gradient always positive or always negative
If we subtract the input by its mean before passing it into the network, the input won’t always be positive, thus resolve the problem
Normalize (Rescale) the Data
Different features often have vastly different scales. For example:
- Age: 20~80
- Income: 30,000~150000
- Height: 150~200 cm Without Normalization, features with large numerical range will dominate the learning process simply due to their magnitude
Hence, we normalize the data making them have the same scale, we achieve this by dividing the data by “standard deviation”
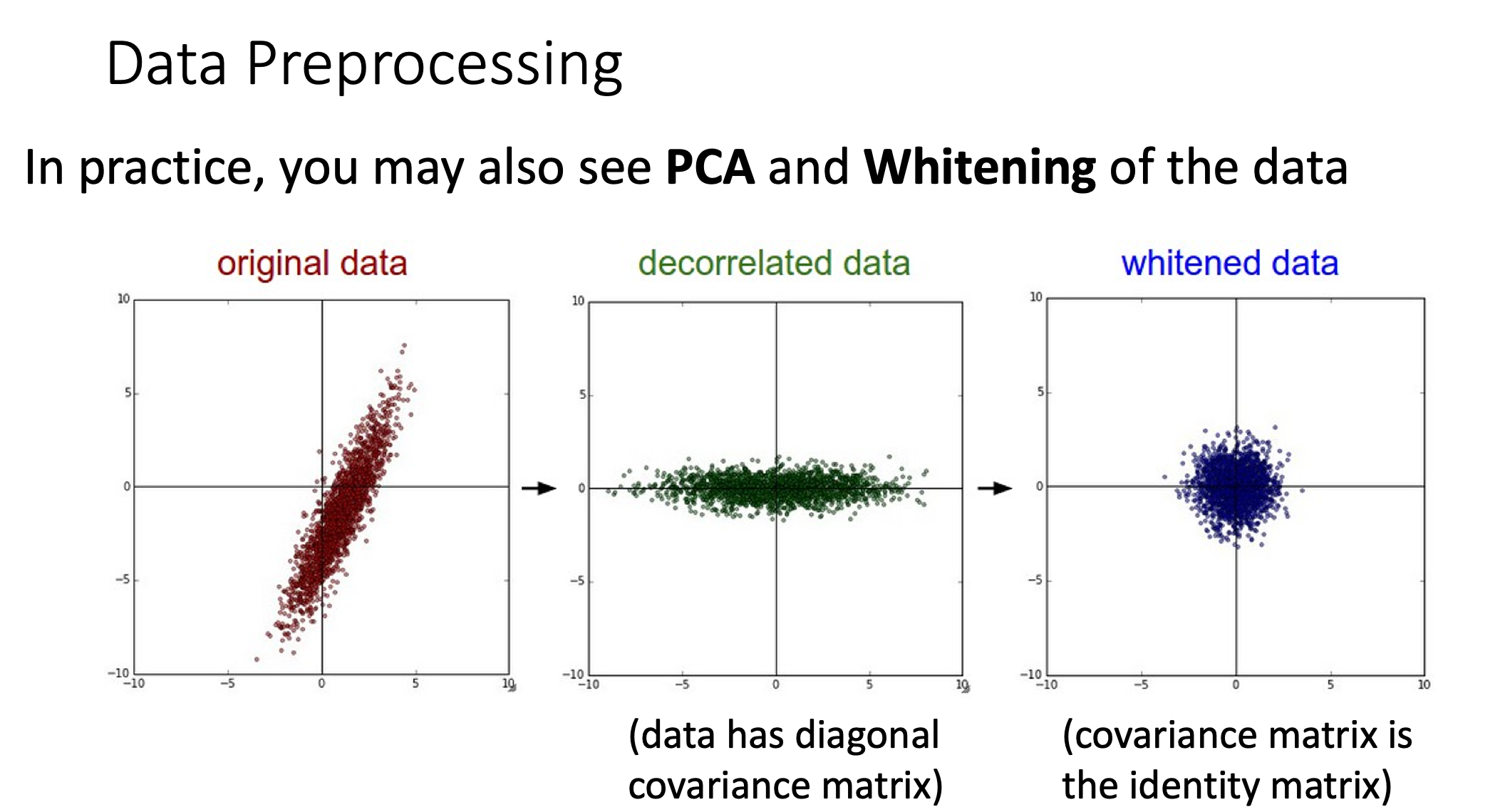
Decorrelated Data
When we train model, we want different feature not to affect each other. Hence, we do some transformation to the data to decorrelate features
Whitened Data
To whitened data is to decorrelate then normalize the data
Why Normalization Helps Optimization
Before Normalization:
- Data points are far from origin
- Decision boundary (line) starts near origin due to weight initialization
- Small weight changes cause large shifts in the boundary relative to distant data
- High sensitivity → difficult optimization
After Normalization:
- Data points cluster around origin
- Decision boundary and data are at similar scales
- Small weight changes produce proportionally smaller effects
- Lower sensitivity → easier optimization
Key Insight:
Normalization aligns the scale of your data with the scale of your initial weights, creating a more stable optimization landscape where gradient steps have predictable, measured effects rather than dramatic swings.