Sigmoid Function
Introduction

- Squash numbers to range
- Historically popular since they have nice interpretation as “firing rate” of a neuron
3 Problems
1. Saturated neurons “kill” the gradients
The Problem:
When inputs to sigmoid have large magnitude (very positive or very negative), the sigmoid function becomes nearly flat, causing its derivative to approach zero.
The Consequence:
During backpropagation, gradients flowing through saturated neurons become extremely small (near zero), effectively blocking gradient flow to earlier layers.
Why This Breaks Training:
Layers before the saturated neuron receive virtually no gradient signal, so their weights barely update. This “kills” learning in the downstream layers, leaving parts of the network unable to improve regardless of how many training iterations you run.
2. Sigmoid outputs are not zero-centered
The Problem:
- In a neural network layer:
- When we compute gradients: Since sigmoid always outputs positive values: for all
The Consequence:
During backpropagation, all weight gradients will have the same sign:
- If the loss is positive → ALL weight gradients are positive
- If the loss is negative → ALL weight gradients are negative
Why This Limits Optimization:
In the weight space, we can only move in directions where all weights change in the same direction (all increase or all decrease together). We cannot move diagonally where some weights increase while others decrease.
This is like being forced only northeast and southwest but not other directions
3. exp() is a bit compute expensive
In contrast with other activation function like ReLU, it is relatively expensive
Tanh
Introduction

Pros and Cons
- Output can be negative, zero, and positive (zero-centered)
- still kills gradient when saturated
ReLU
Introduction

Problems
1. Not zero-centered output
Same as sigmoid
2. When input , the downstream neuron died
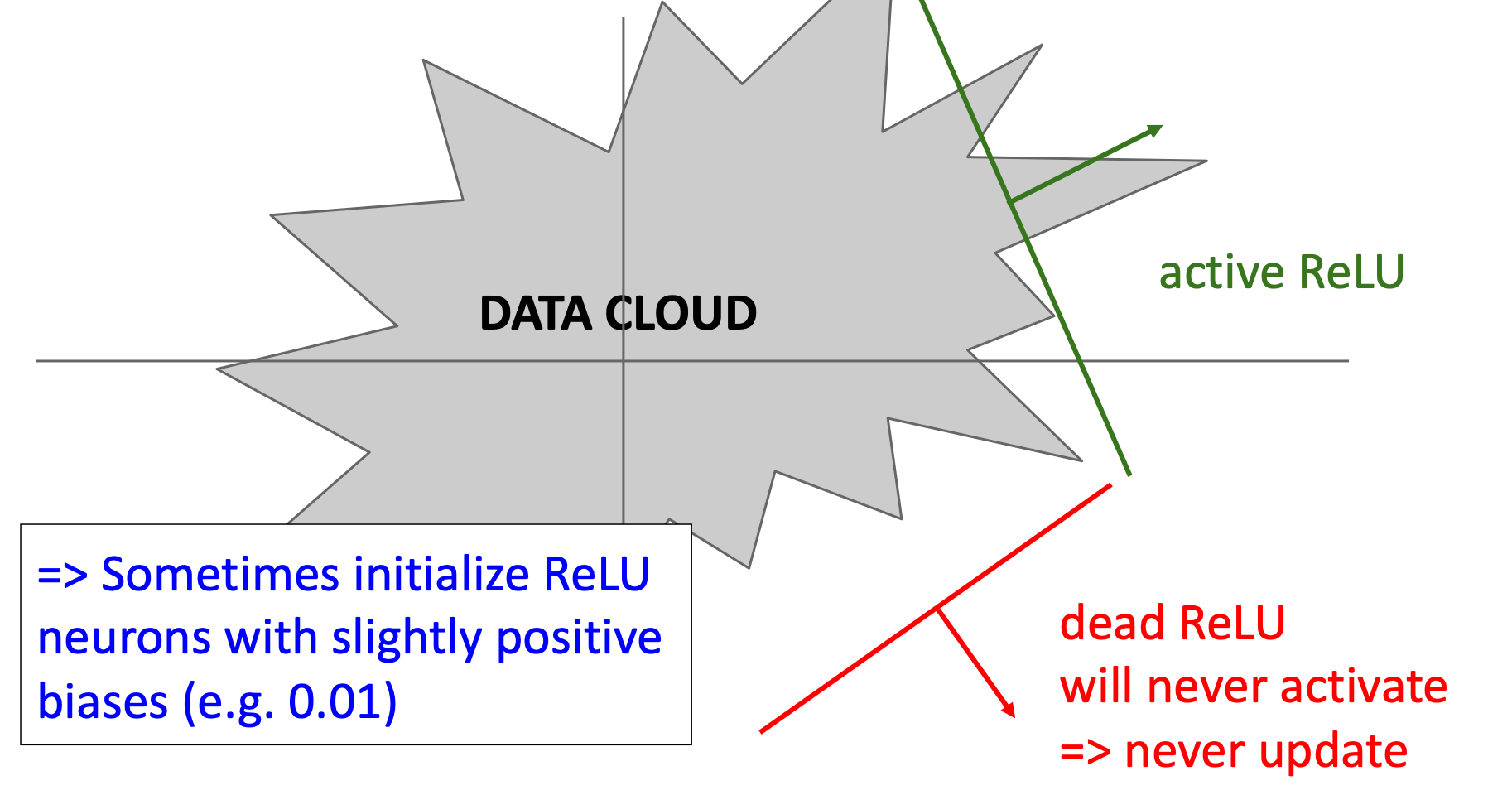
Problem: When ReLU input :
- ReLU outputs 0
- Gradient
Consequence: Zero gradient blocks backpropagation:
- Upstream weights get no gradient signal
- No weight updates occur
- Weights remain unchanged
Result: Dead neuron cycle:
- Same weights → same negative input → same zero gradient
- Neuron permanently “dies” and never recovers
- Lost computational capacity
A way to prevent
We can initialize biases with slightly positive value instead of 0, which gives neuron opportunity moving out of “dead region”
Leaky ReLU
Introduction

where is a hyperparameter which often set to
Pros and Cons
Pros:
- Does not saturate
- Computationally efficient
- Converge much faster than sigmoid/tanh
- will not “die” (because no derivative equals 0)
Cons:
- not differentiable
Exponential Linear Unit (ELU)

is a hyperparameter and is usually set to
Pros and Cons
Pros:
- All benefits of Leaky ReLU
- Differentiable at
Cons:
- Require exp() computation
Summary
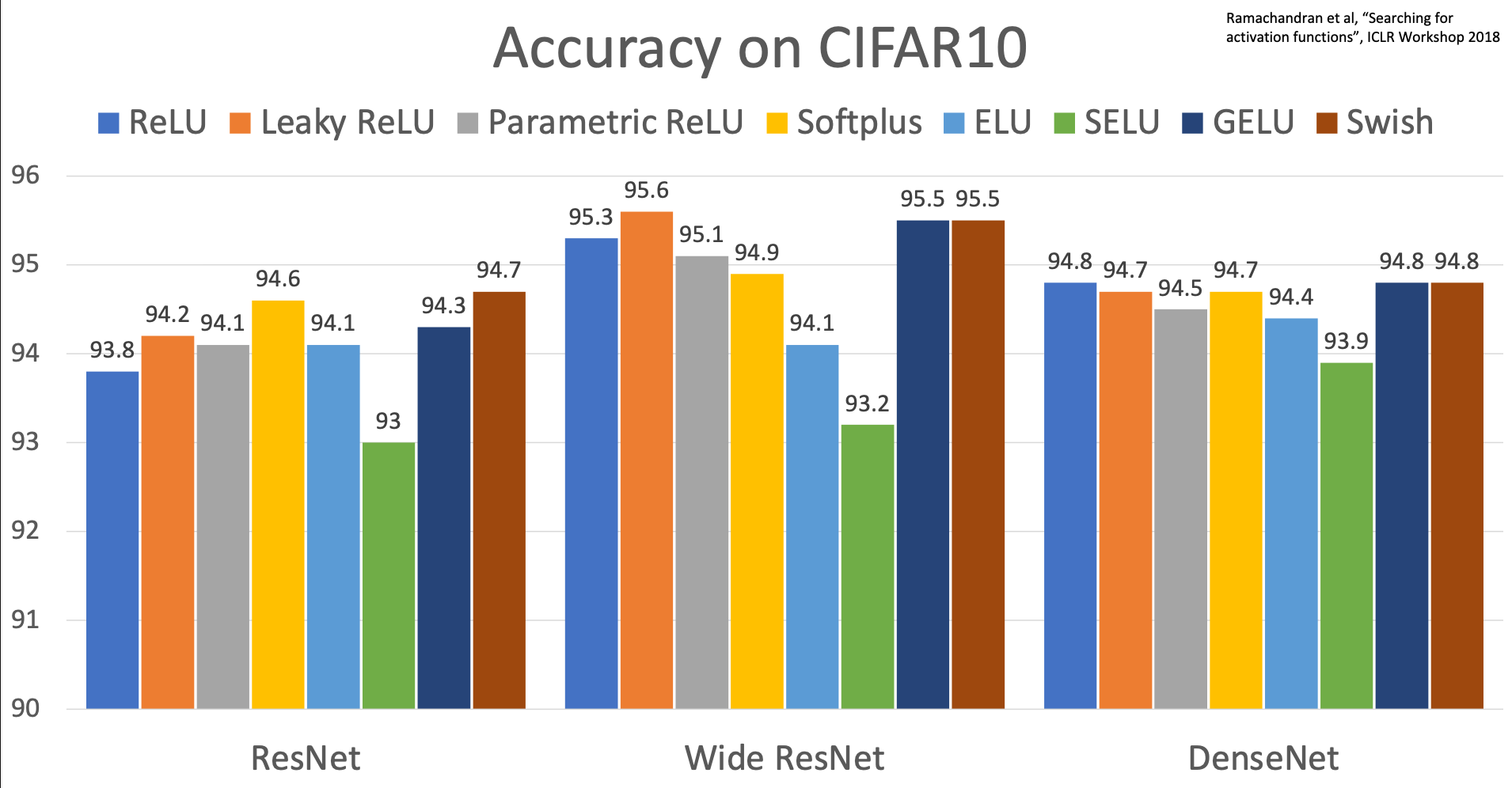
- Don’t think too hard, just use ReLU
- Try Leaky ReLU / ELU / SELU / GELU if we need squeeze last %
- Never use sigmoid or tanh