Introduction
Introduction
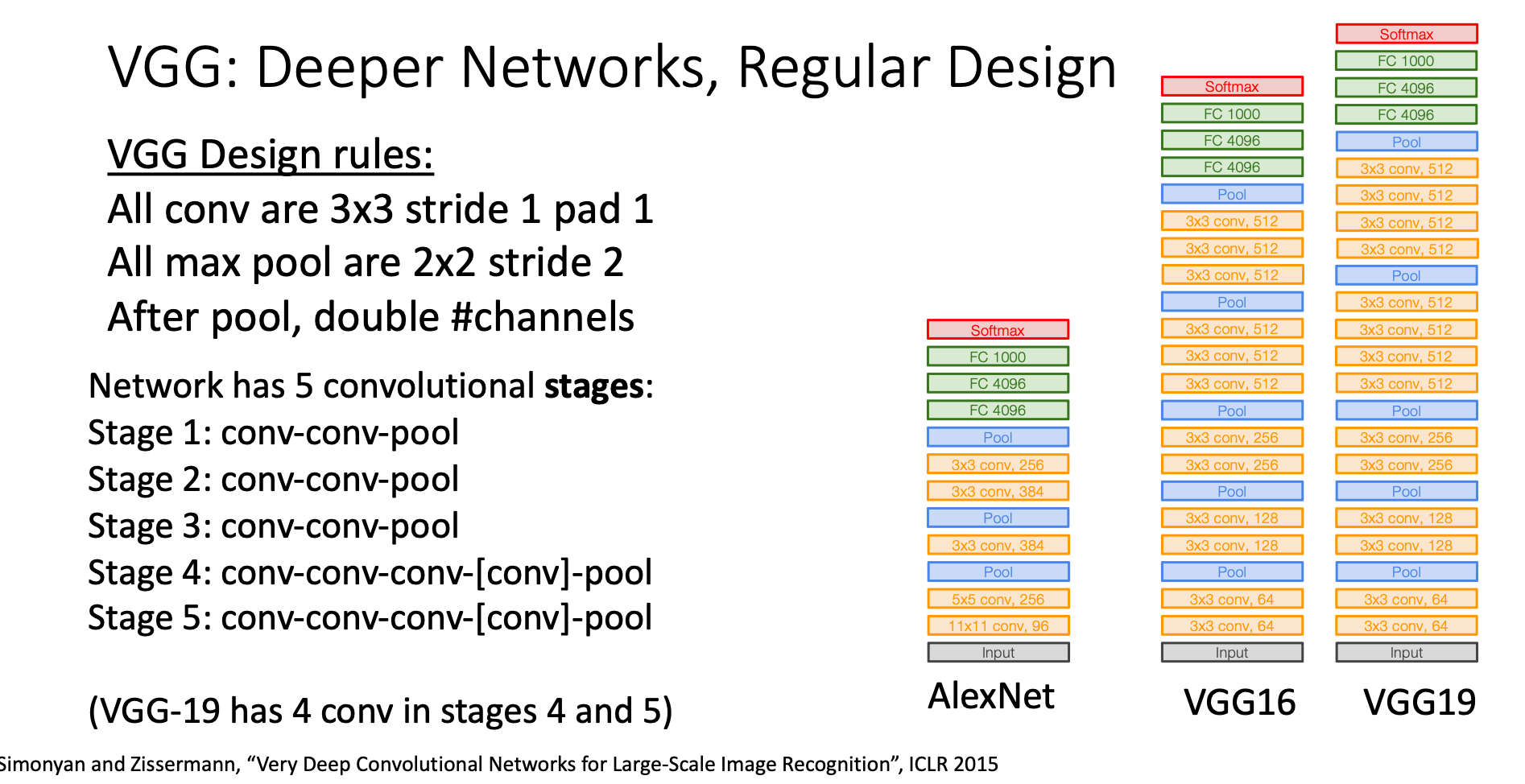
VGG network consists of 5 stages, each of them is made up of several Conv layer with filters and a max pooling layer
Importance
Before VGG, designing CNN architectures was largely guesswork. Researchers experimented with different layer combinations without clear guidelines, making it difficult to understand why certain designs worked better.
VGG changed this by introducing systematic design principles. Instead of random experimentation, VGG demonstrated that CNN architecture could follow logical, predictable rules.
Design Principles in VGG
1. All Convolutional Layers are Stride 1 Pad 1
Statement
Every convolutional layer in CNN should only use layers with filter with stride 1 and pad 1
Reason
| Layer | Parameters | FLOP |
|---|---|---|
| Conv(5x5, C→ C) | ||
| Conv(3x3, C → C)+Conv(3x3, C → C) |
If we stack conv together, then the receptive field of them are . From the above comparison we can observe that stacking multiple conv is better than using a in many ways:
- Use less parameters
- Require less FLOPs
- We can insert ReLU between each conv, which create more nonlinearity and makes the network deeper, and we’ve proved deeper is better in neural network
2. All Max Pooling are Stride 2 and double “channels” after poolings
Statement
The max pooling will cut the size of and by half, then the subsequent conv will make the number of output channels double
Reason
| Input | Conv | Memory | Parameters | FLOPs |
|---|---|---|---|---|
| Conv() | ||||
| Conv() |
The goal of doing the pooling operation is to extract important information from the image, so that slightly changing the image won’t cause much influence to the prediction.
We want every convolutional layer in CNN to have the same FLOPs, thus as we see on the above table, doubling the channel after max pooling can maintain FLOPs
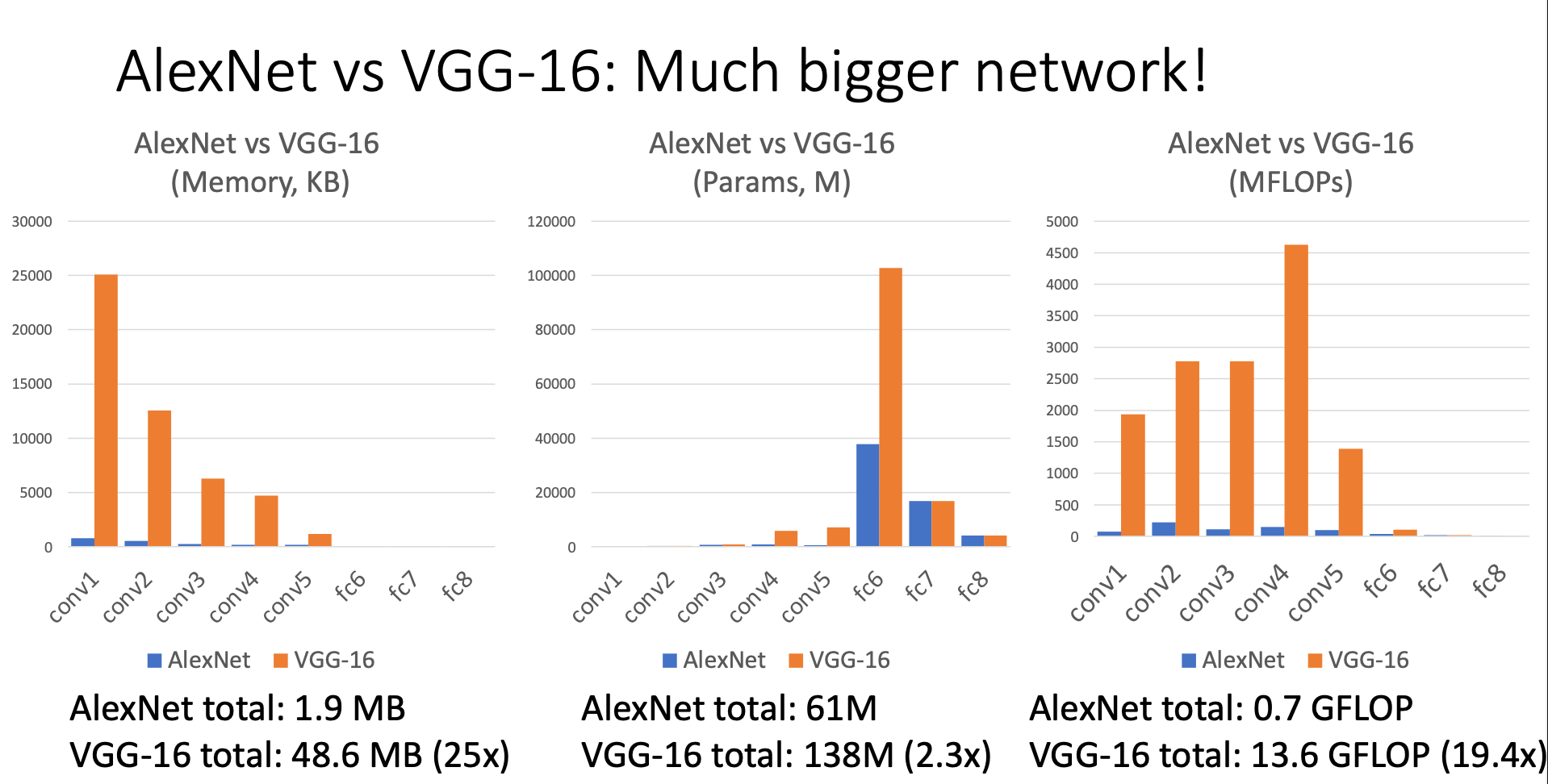
Computation Resource Usage