What is Convolutional Layers
Definition
Convolutional layers use small learnable filters (kernels) that slide across input data to detect local patterns and features.
A neuron in CNN is said to contribute exactly one value to the output feature map
How It Works
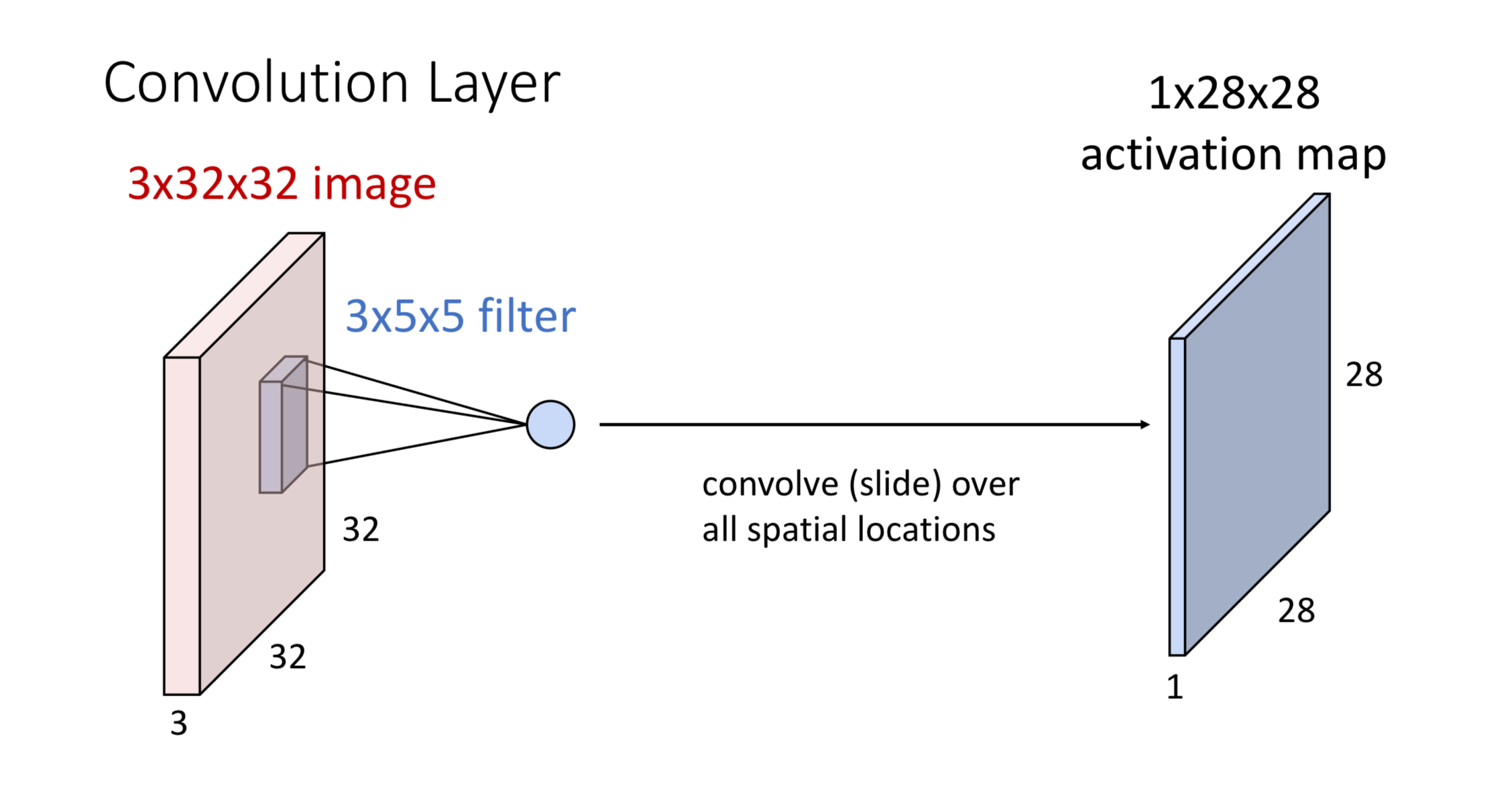
The Process:
-
Create Filter: Make a 3×5×5 kernel (depth matches input image depth)
-
Slide Across Image: Move the filter left-to-right, top-to-bottom over the entire image. At each position, calculate the dot product between filter and image patch.
-
Generate Output: Each dot product becomes one value in the activation map. All values together form the final 28×28 output.
Generalization
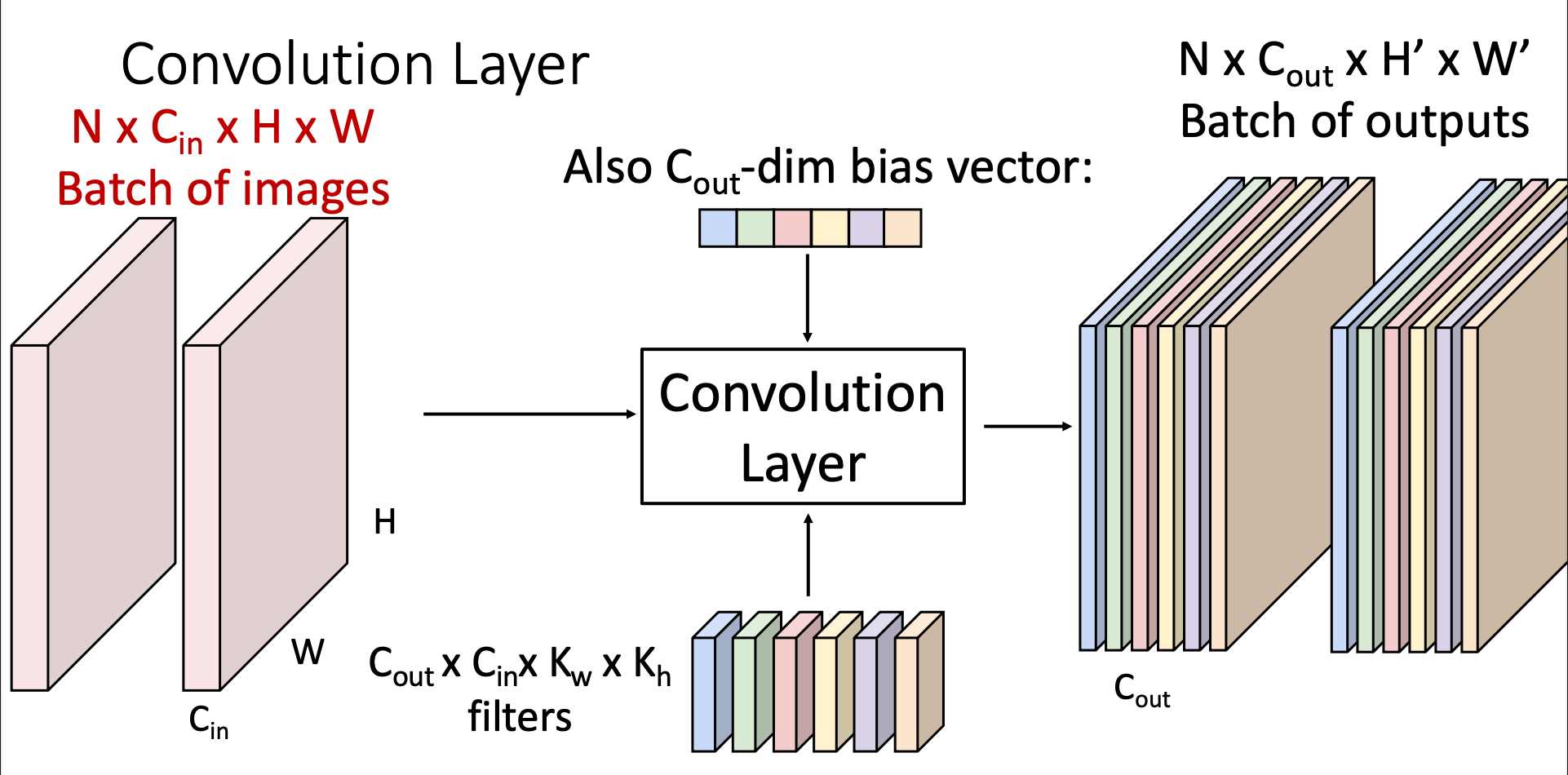
Parameters
| Parameter | Explanation |
|---|---|
| Number of images in a batch | |
| The number of channels in the input image | |
| 1. The number of filters in the convolution layer 2. The number of channels in the output | |
| , | The width and height of the filters |
Explanation
Input: The input has images, each with the size and channels
Convolutional Layer: In a convolutional layer, we can have multiple filter. The number of filters is , which also determines the number of channels in the output
Every filter only has one bias value: I-20250722-Bias_in_ConvLayer
Output (Activation Map): We’ll have outputs, each has channels, the width and height is determined by both the input image and the size of filter
Stacking Convolutional Layers
If we stack two convolutional layers like that we do in linear classifiers. We’ll then get a new convolutional layer that combines the operations we’ve done with two layers into one
Thus, we’ll also put in an activation function after each convolutional layer
What do Convolutional Layers Learn
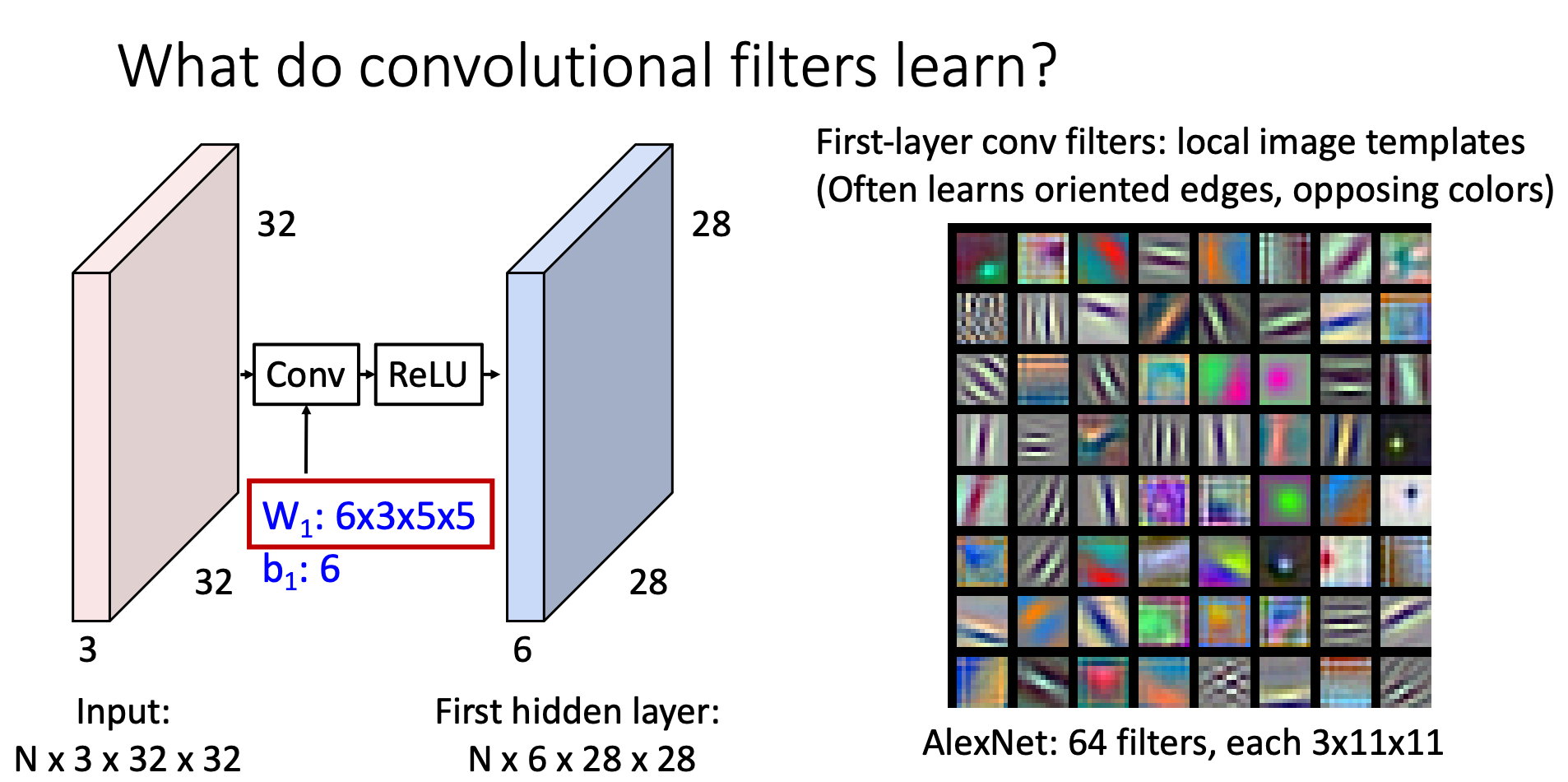
The filters in the front layers will often learn patterns like oriented edges, opposing colors. The latter layers will then learn larger patterns
This kind of conv layer is called "2D convolution", there are also 1D conv, which can be used for NLP and 3D convolution, which can be used for 3D computer vision
Padding
Introduction
In previous section, we’ve learnt that the width and height of the convolutional layer’s output can be calculated through .
This suggests that feature map “shrink” with each layers, which limits the number of layers we can have in neural network
The concept of “padding” aim to deal with this problem
How Padding works
Before sending the feature map into the convolutional layers, we’ll add additional width and height to the feature map, which is often set to 0
There are also other ways filling the additional features added by paddings
Then, since we’ve increase the size of feature map, the activation map will then have larger width and size based on our choice of padding
A common choice of padding is , since this makes the output the same size as the input. This specific padding is called "same padding"
Receptive Field
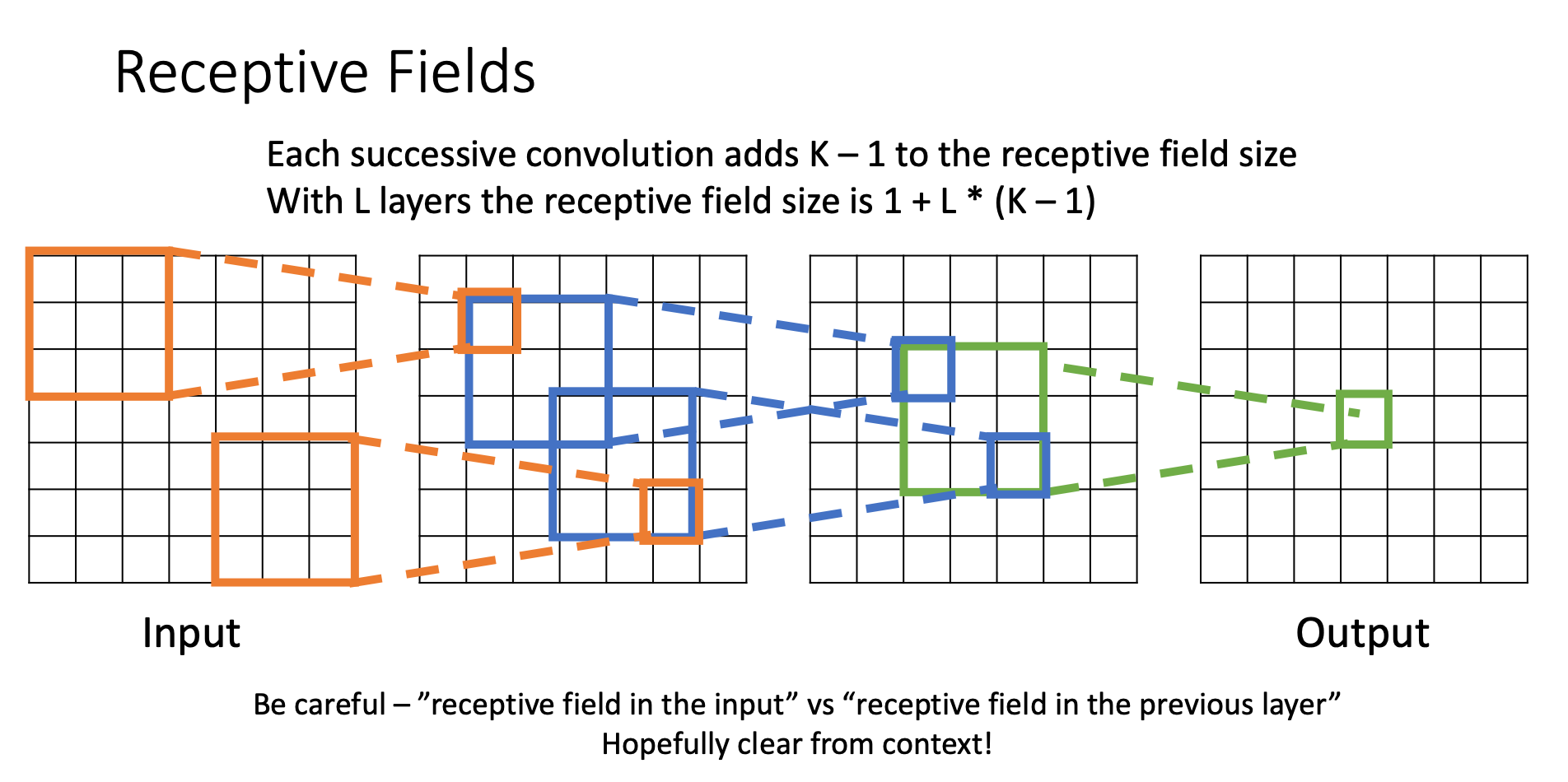
For a convolution with kernel size , each element in the output depends on a receptive field in the input
Each successive convolution adds elements to the receptive field
With layers the receptive field in the input is
Strided Convolution
Motivation
For large images, i.e., images with lots of pixels, we need lots of layers for each output to see the entire images (since each layer only add to the receptive field)
Hence, we introduce the concept of “stride convolution”
How does it works?
Stride convolution is a technique where the filter moves across the input with steps larger than one pixels. This not only decrease the spatial dimension of the output feature map, but also increase the increment of receptive field per layer
With the technique applied, the current output dimension can be calculated by
We call the process of reducing spatial resolution of feature map while preserving important information "Downsampling"
Common Settings of Convolutional Layers
General Rules
- Square kernels:
- Padding:
- Channels:
Standard Configurations
| Purpose | |||
|---|---|---|---|
| 3 | 1 | 1 | Standard conv |
| 5 | 2 | 1 | Large receptive field |
| 1 | 0 | 1 | Channel Mixing |
| 3 | 1 | 2 | Downsample |
Channel Mixing ( CONV)
What it does: Takes all channel values at each pixel location and combines them using learned weights.
Think of it as: Running a mini fully-connected network independently at every pixel position.
Example:
- Input: 3 channels at pixel → values
- Output: 1 channel → learned combination like
- This happens simultaneously for all pixels in the image
Unlike regular convolution that mixes spatial neighbors, conv only mixes channels at the same spatial location.
This kind of convolutional layer reduces the spatial dimension by half