Image Classification
Definition
Image classification is a computer vision task where we want the algorithm to assign predefined labels to images based on their content
Problem: Semantic Gap
While human interpret images in terms of meaningful objects, emotions, and abstract concepts, computers process images as pixels, colors, etc.
This let training computer to “understand” images a hard thing
Challenges
1. Viewpoint Variation
If we slightly change the shooting angle photographing a cat, the pixel value in the image change drastically
2. Intraclass Variation
Intraclass Variation refers to the difference appears in the same categories.
For example, a cat can be white, orange, black… They’re very different in pixels, but they’re the same species
3. Fine-Grained Categories
It refers to classification class distinguishing between very similar subcategories within broader class
For example, face recognition requires the computer to distinguish between very similar objects
4. Background Clutter
Sometimes the object has very similar colors or patterns to the background, it’ll be hard to detect the objects in these kinds of picture
For example, 竹節蟲
5. Illumination Changes
Pictures can be taken in different light condition, we want to classify objects from same categories but different illumination in this type of tasks
6. Deformation
The images from the same categories can come in different shapes and structures. This cause intraclass variation
For example, a cat sitting vs. stretching vs. standing
7. Occlusion
Sometimes parts of an object are hidden or blocked by other objects. Occlusion refers to this kind of image classification tasks
For example, a cat under the sofa with only tail visible in the image
Image Classification as Building Block for Other tasks
Object detection, image captioning and many other tasks use image classification algorithms as building part of their algorithms. These will be discussed in later lectures
Image Classification Dataset
MNIST
Introduction: MNIST is a dataset contains digits from 0 to 9, results from MNIST do not often hold on more complex datasets since it’s too simple. However, you can use it to check if your theory works
Properties:
- 10 classes: Digits 0 to 9
- grayscale images
CIFAR10
Introduction: CIFAR10 is a dataset contain RGB images for 10 classes. Although the dataset is relatively small, it’s still challenging since the images in the dataset are hard to recognize
Properties:
- 10 classes
- RGB images
CIFAR100
Introduction: It’s a larger version of CIFAR10
Properties:
- 20 superclass with 5 classes each
- e.g., Trees: Maple, oak, palm, pine, willow
ImageNet
Introduction: Widely recognized dataset such that if you want to publish a paper but not having ImageNet as benchmark, your paper will be very likely to be rejected
Performance Metric: We use “top-5 accuracy” as our method measuring our prediction. If the correct class is among the top 5 predictions of the model, we view it as a successful classification
Properties:
- 1000 class
- 1.3 million training images, 50k validation images, 100k test images
Omniglot
Introduction: 1623 categories of alphabets, and 20 images per category. This dataset is meant to test few shot learning, where we want to create great classifier based on small number of images
Properties:
- 1623 categories but 20 images per category
Nearest Neighbor Classifier
Hyperparameters
Definition
Hyperparameters are choices about our learning algorithm that we don’t learn from training data; instead we set them at the start of the learning process
For example, and distance metric in -nearest neighbors
The choice of hyperparameters is very problem-dependent, which means in general we need to try them all the see what works best for the task
Setting Hyperparameters
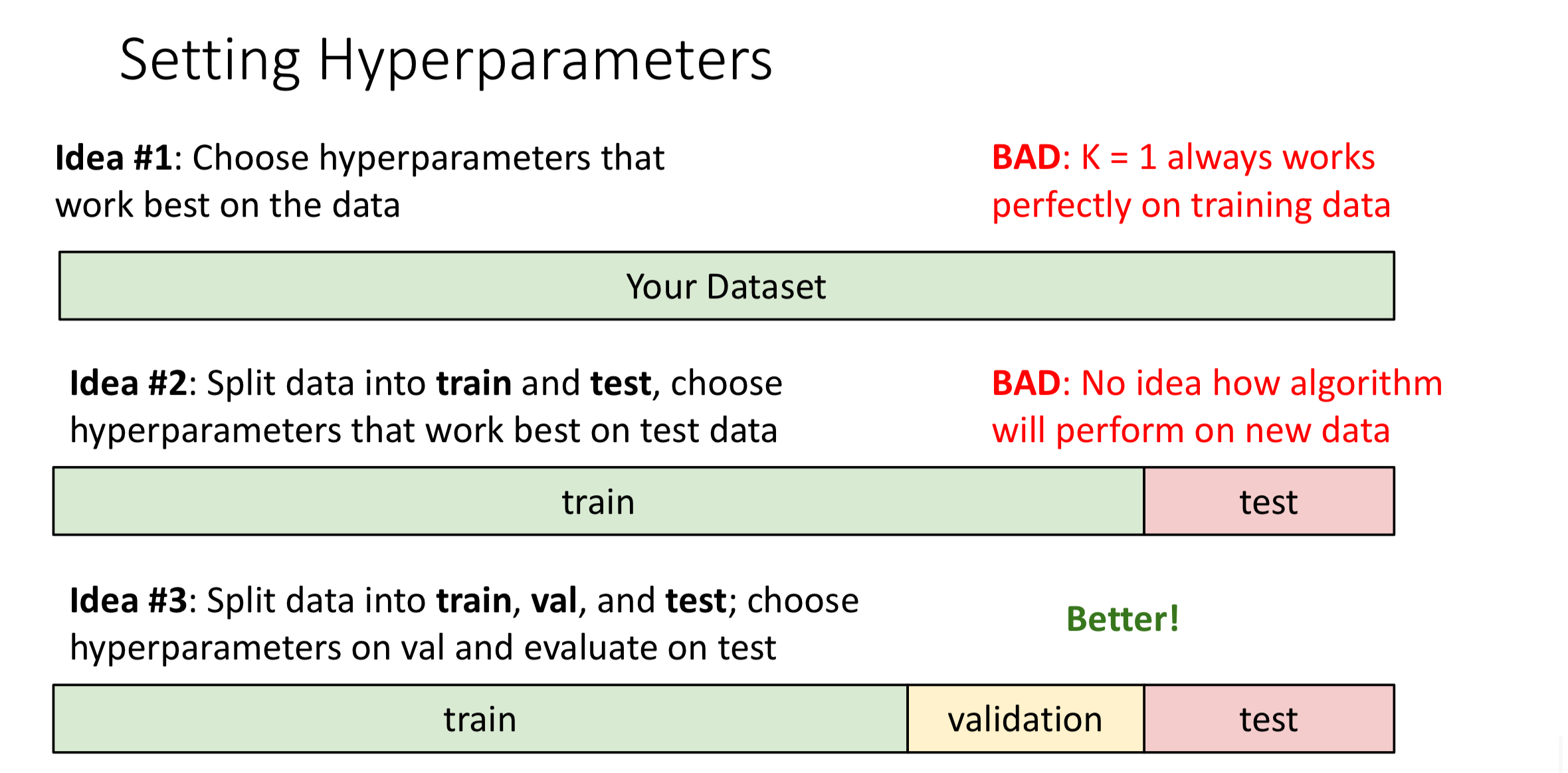
Train, Test, Validation Method
Idea: Split data into train, val, and test; choose hyperparameters based on val and evaluate our model on test
Comment: Better, the test data will be clean during the training process, and we can know how the algorithm perform on new data with test
When writing a paper, we can only evaluate with test in the final period (like 1 or 2 weeks before handing out paper) since if we evaluate with test in the early stage. The outcome will affect our training decision, which pollutes the test data
Cross Validation
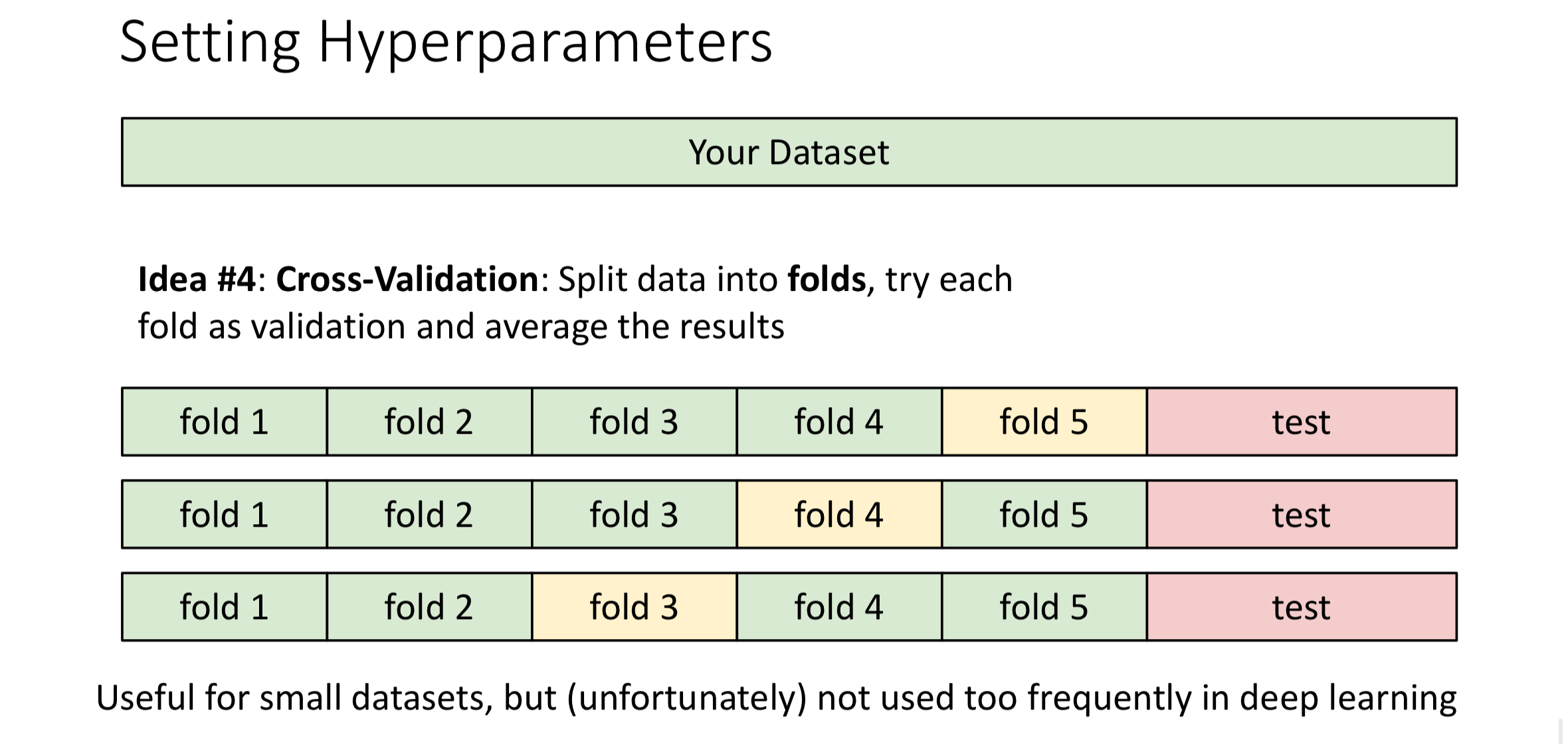 Idea:
Split data into folds, one at a time, we’ll use one fold as validation data and others as training data. Then we’ll average the result
Idea:
Split data into folds, one at a time, we’ll use one fold as validation data and others as training data. Then we’ll average the result
Comment: Best, it is useful for small datasets. However, when encountering large dataset, this will consume lots of computing resources, thus not used frequently in deep learning