Hashed Page Table
Motivation
64-bit 系統用普通方法或 hierarchical page table 會讓 page table 的大小爆炸,hashed page table 就是為了解決這個問題
Philosophy
不預留 entry 給沒用到的 page,只紀錄實際用到的 page
How it works?
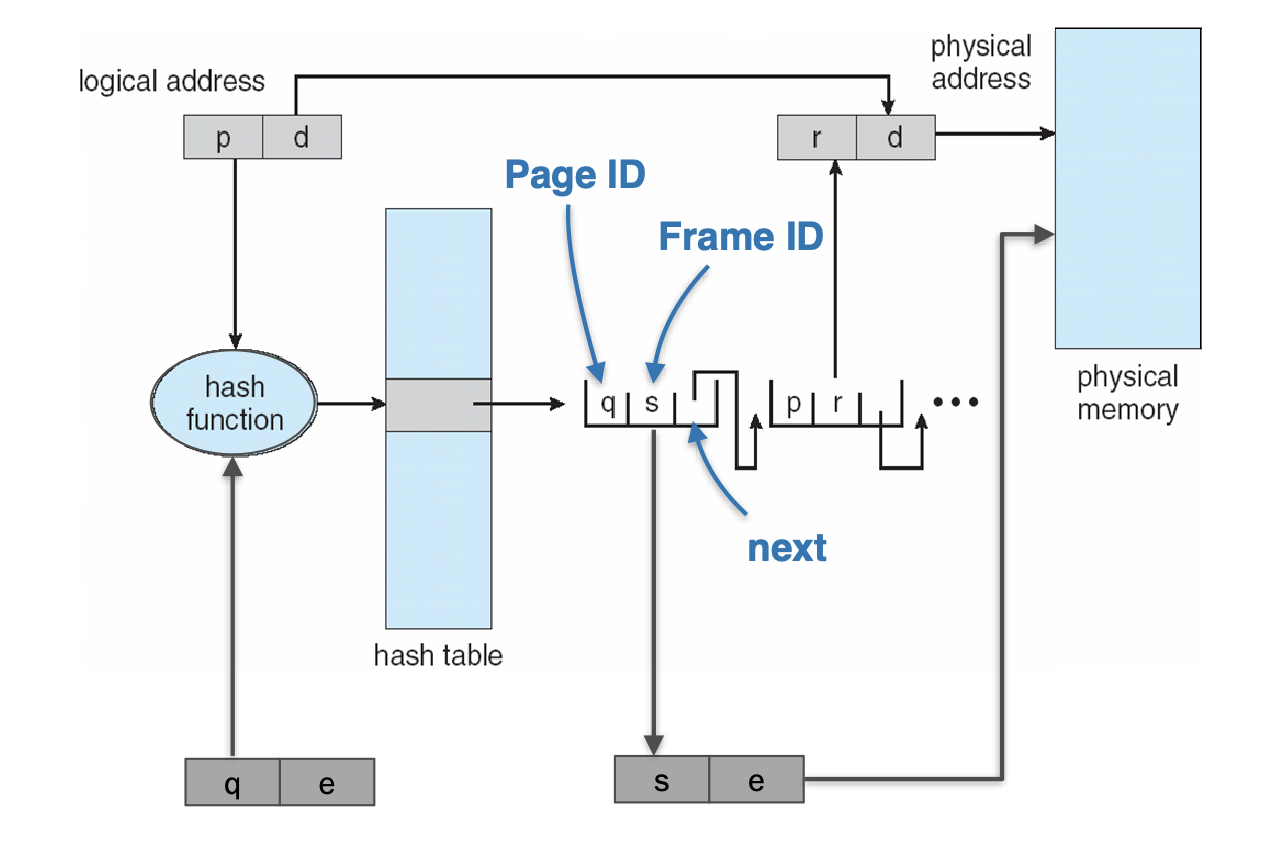
- CPU 請求 對應的 physical address
- 把 丟進 hash function 得到 hash 值,這個值指向 hash table 的某一個 bucket
- 每個 bucket 指向一個 linked list,我們走訪整個串列找到我們要的 entry,linked list 的每個節點包含三個欄位
- Page ID:page 編號
- Frame ID:page 對應的實體 frame 編號
- Next Pointer:指向 linked list 下一項
Clustered Page Table
Motivation
對於 64-bit 系統,普通的 hashed page table 查找效率太低
Resolution
我們讓 linked list 的每一個節點(cluster)同時對應多個 pages(像是 16 個 page),查找流程會變成
- 我們想找編號 1003 的 page
- 將 1003 除以 16,得到 cluster 起點 = 1000,餘數 = 3
- 將 1000 拿去 hash 後在對應的 linked list 找到 page ID = 1000 的 cluster
- 直接取此 cluster 第 3 格的 frame ID
[cluster編號 | 框0 | 框1 | 框2 | ... | 框15 | next]