How it works?
Encoder & Latent (Hidden) Feature
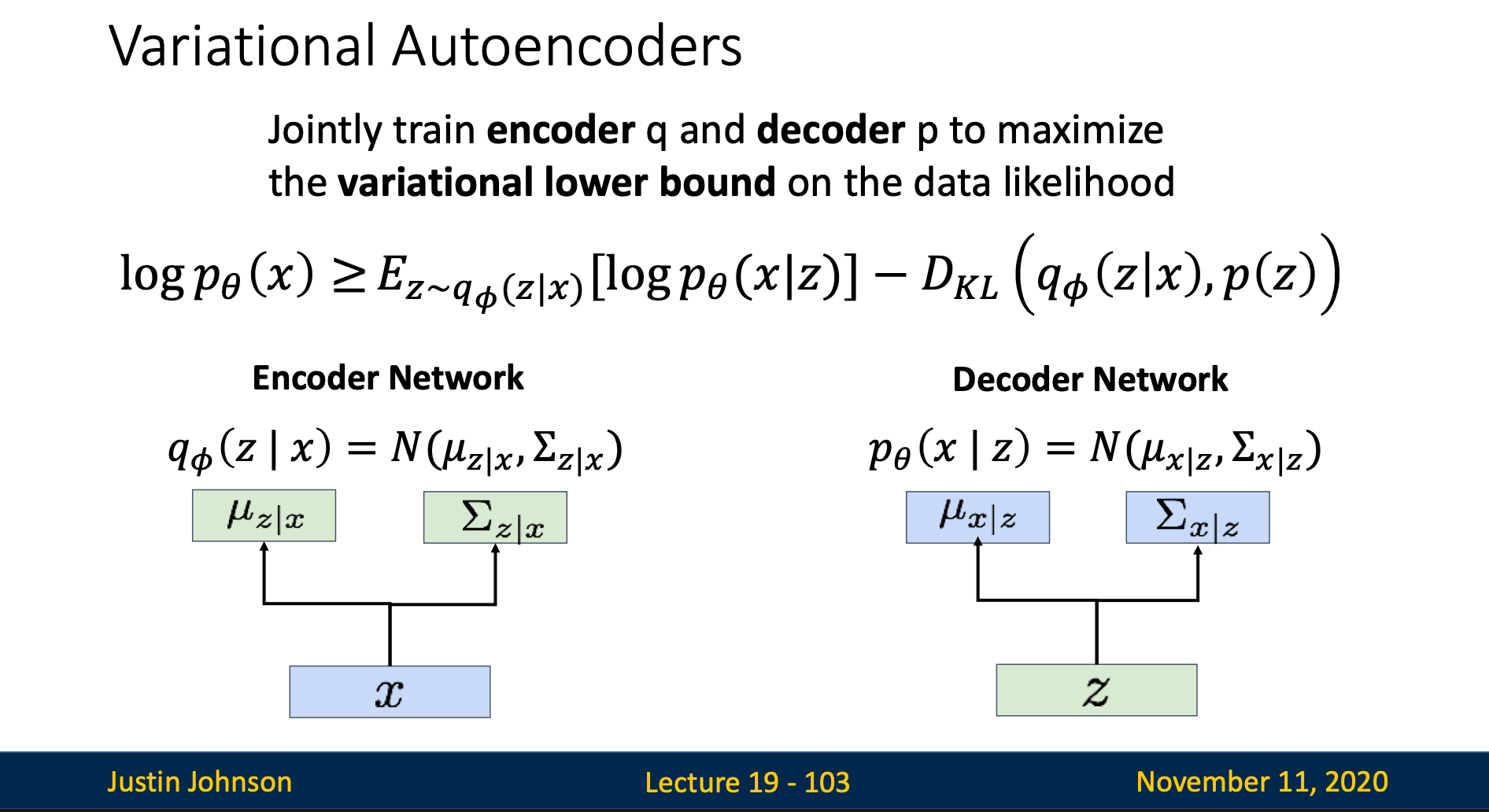
For every input image , we try to guess “which latent feature will generate this image ?” We achieve this guess by using an encoder to encode the input image into latent feature
However, since we are just guessing the latent feature, we don’t know the exact . Hence, we express as probability distribution
In summary, the encoder in variational autoencoder output a mean and a variance which tells us the distribution of (normally Gaussian distribution)
Decoder
Step 1: Sample
The decoder input and output . In last section, we mentioned is a probability distribution, thus in order to pass it into the decoder, we sample a specific using the given distribution
Step 2: Decode
Now, we pass our sampled into the network. The output of the decoder is also a distribution, which mean the decoder also output a mean and a variance
Step 3: Get generated image
To get the final output image, we have two choices
- sample from the distribution
- use the mean
means the learnable parameters of the network
Hence, means “the probability of , given learnable parameters “
How do we train the model?
Basic Idea
If we input , we want to maximize the output image probability distribution of generating exact input
Idea 1: Integration
Mathematical Expression
We want to find that maximize - the probability of generating given learnable parameters
Since is also a distribution, we need to marginalize the calculation
Problem
However, we can’t integrate over since has infinite number of possibilities
Idea 2: Bayes’ Formula
Mathematical Expression
Problem: Unable to Compute
means “given input image , what is the probability of latent feature ”
This is what we want the encoder to learn!!! The encoder wants to learn the best probability distribution for , so we can’t know the exact for sure
Solution: Approximate by
We use a new network to approximate
is fixed. It is our belief in what should distribution looks like before we look at input data . Normally we choose Gaussian distribution with mean 0 and variance 1
Mathematical Detail Finding Lower Bound for
What is ?
We train encoder and decoder together in the training process
Steps
Step 1: Change Bayes’ Formula Representation
Step 2: Wrap
Since doesn’t depends on , so we can wrap it with expectation:
Thus the Bayes’ formula can then be organize to
Step 3: Observe Lower Bound
KL >= 0, so dropping the last term gives lower bound on
This gives us the lower bound of
Training Process
Encoder
The corresponding term for encoder in lower bound formula is:
This term tells us in order to let the lower bound higher, we want the distribution of and to be close, which will give us divergence nearly zero
KL divergence goes to zero when the two distributions is about the same, and large if two distributions are different
is predefined, normally
Decoder
The corresponding term for decoder in lower bound formula is:
This term mean
- Sample from
- Compute the weighted average of across all possible values, where the weights are given by
- This measures: “For the given distribution, how likely can it reconstruct the input image ?” We want to maximize this expectation

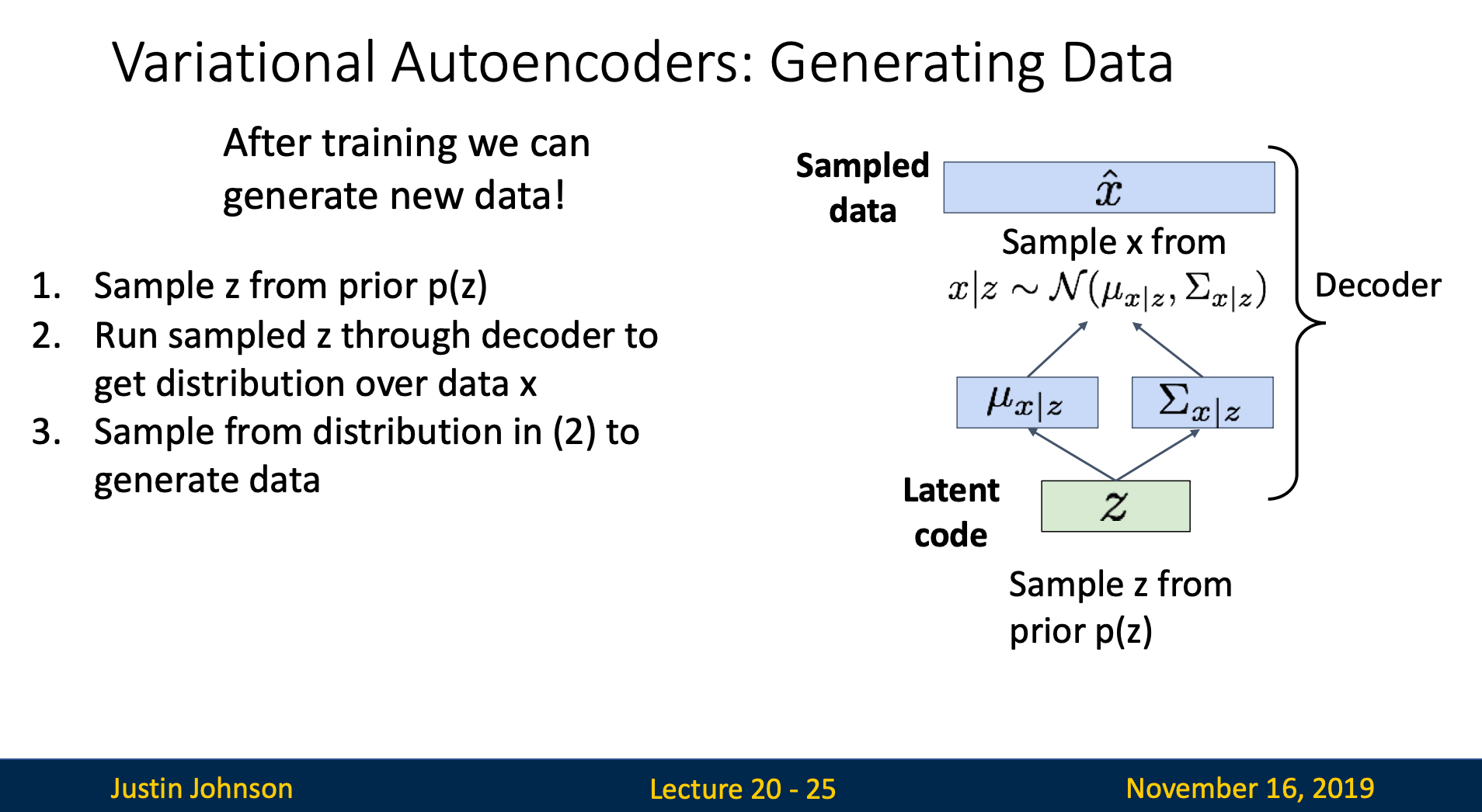
Generating Data
- Sample from prior
- Pass into decoder
- We should get which resembles the training input image
Pros & Cons
Pros
- The mathematical foundation of the model make them interpretable and theoretically well-understood
- The encoder learns meaningful latent feature, which can be used for downstream tasks
Cons
- VAEs optimize the lower bound, but not the exact likelihood
- Samples blurrier and low quality compared to GANs