What is Autoencoders?
Difference with Regular Encoders
In regular encoders, we need label to optimize our encoder.
However, most of the data in the world doesn’t have label. Hence, the goal of autoencoder is to optimize our encoder without the help of label
How Encoder Works?
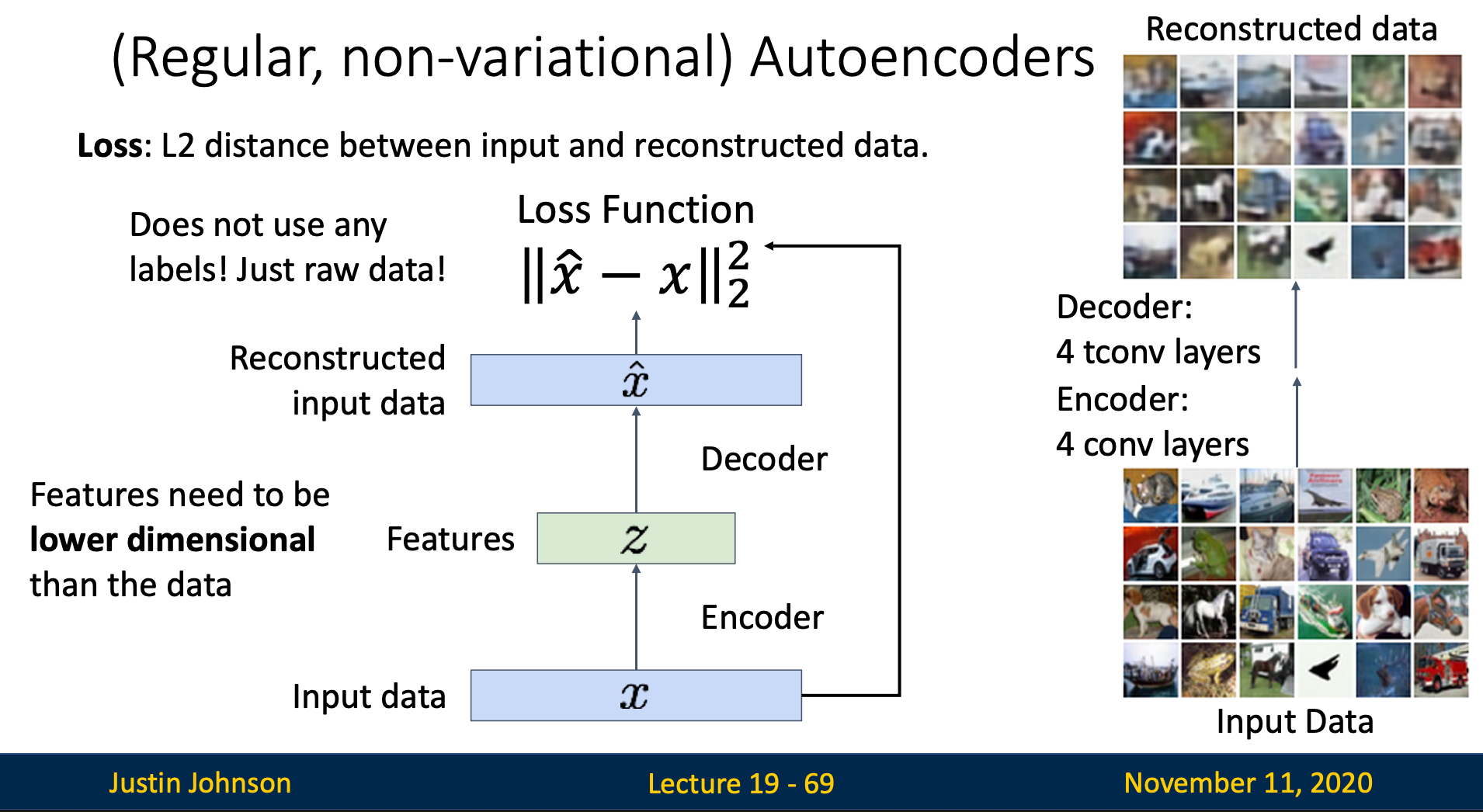
We pass in our input data , and the encoder should compress and reorganize, then output a feature vector
Implementation
How we optimize without label ?
After encoding, we’ll end up with a feature vector, this feature vector should contain compressed information about the input
Hence, we try to decompress the feature vector with a decoder, then compare the decoder’s output and the encoder’s input to compute the loss
Feature vector should have lower dimension than input
Reason 1: Prevent Trivial Solutions
If feature vector’s dimension is too large, the network can simply learn the identity function, which is bad
Reason 2: Force Compression and Feature Learning
If the vector has small dimension, we force the encoder to extract important features in order to fit in the feature vector
Reason 3: Enables Generalization
With limited dimensions, the encoder must extract generalizable features rather than specific training example
How we use trained encoder?
After training, we remove the decoder and use encoder for a downstream task (transfer learning)
Autoencoder can used to initialize supervised model
![]()