Simplified Attention Layer
1. Input
- Query Vectors:
- Input Vectors:
- Assumption: For the dot product to be valid, we must have
2. Computation
- Alignment Scores (): Measures the similarity between and each row
- Attention Weights (): Normalize scores into a probability distribution.
- Output Vector (): A weighted sum of the inputs.
Why Scale by ?
As grows, the variance of the dot product increases. Large scores push the softmax into regions with extremely small gradients (“saturation”), leading to vanishing gradients during backprop. Scaling keeps the variance near 1.
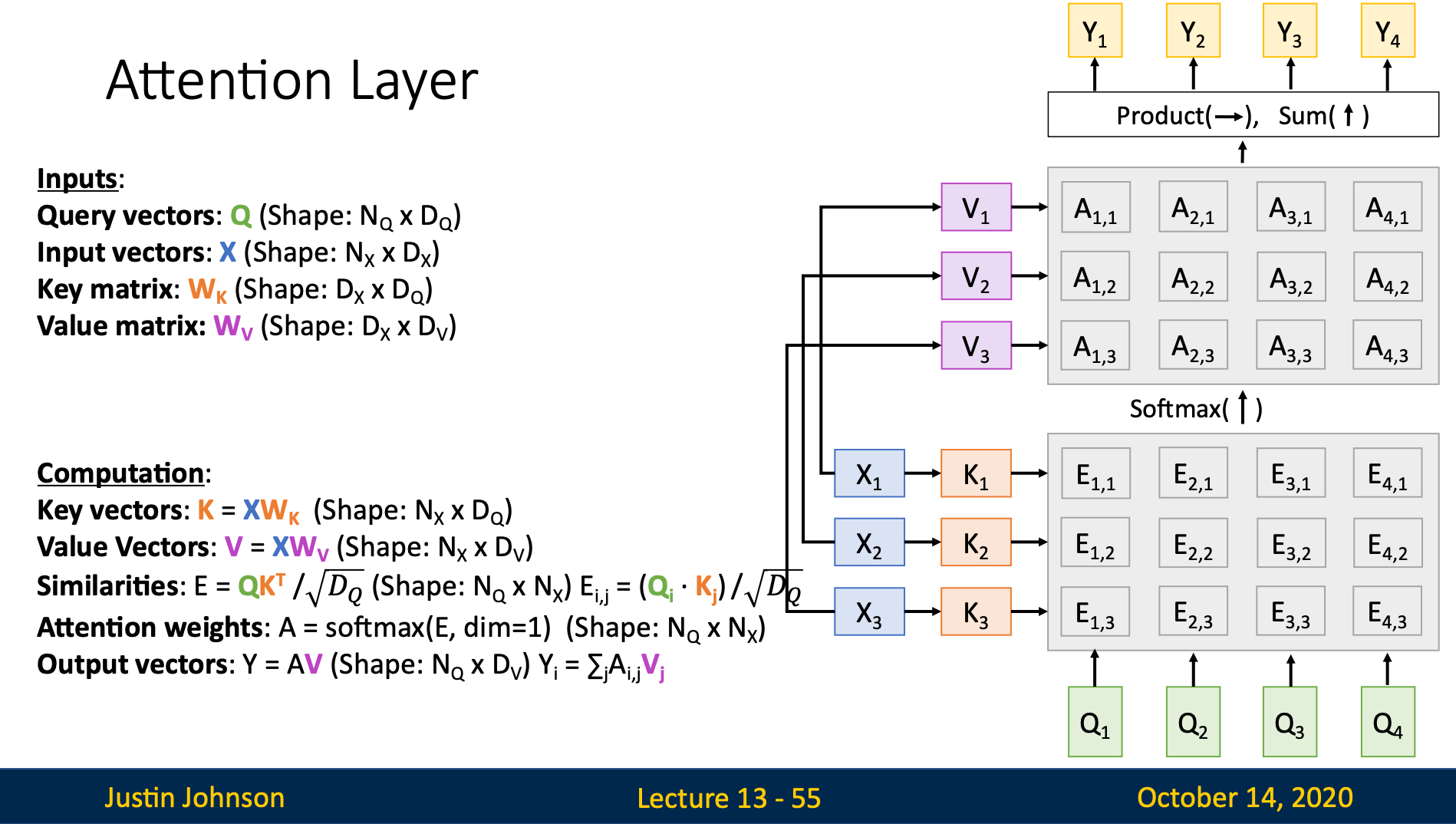
Standard Attention Layer
1. Introduction
In practice, we don’t just use the raw input . We project it into different spaces for “matching” (Key) and “extracting” (Value).
2. Input
- Query Matrix:
- Input Matrix:
- Weight Matrices:
- (Projects query to internal dim)
- (Projects input to key space)
- (Projects input to value space)
3. Computation Pipeline
- Linear Projections:
- Similarity Matrix ():
Each is the score between the -th query and -th key.
- Attention Weights ():
- Final Output ():
This is a “row-wise” combination: each row is a weighted sum of all rows in , i.e.,
4. Query, Key, and Value Vectors
We can observe that both alignment scores and output vector use input vectors in its computation. However, they serve for different purposes
- in alignment scores: it serves purpose for pattern matching
- in output vector: it acts as actual info contain in input
Since they serve for different purposes, we can use learnable parameters to optimize them for separate use
Key Vector
The key matrix learns what features do the query vector wants to match, then will extract desired features from the original input vector
Value Vector
The input vector mix all the features in the image together, value matrix learns to extract valuable features from the image to send to the next layer
Query Vector
It contains the current context we have. We can think of it as saying: “Based on the context in the first periods, what part of the input should I look at to generate the next output”
5. Deep Dive: Training vs. Inference
Training
We use Teacher Forcing. Since the entire target sequence is known, we can compute all Queries () at once. The “dependence on previous step” is bypassed by using the ground truth.
Inference (Generation)
We must process Autoregressively. The Query for step depends on the output generated at . Here, parallelization only happens across the “Input” side ( and are static), not the “Query” side.