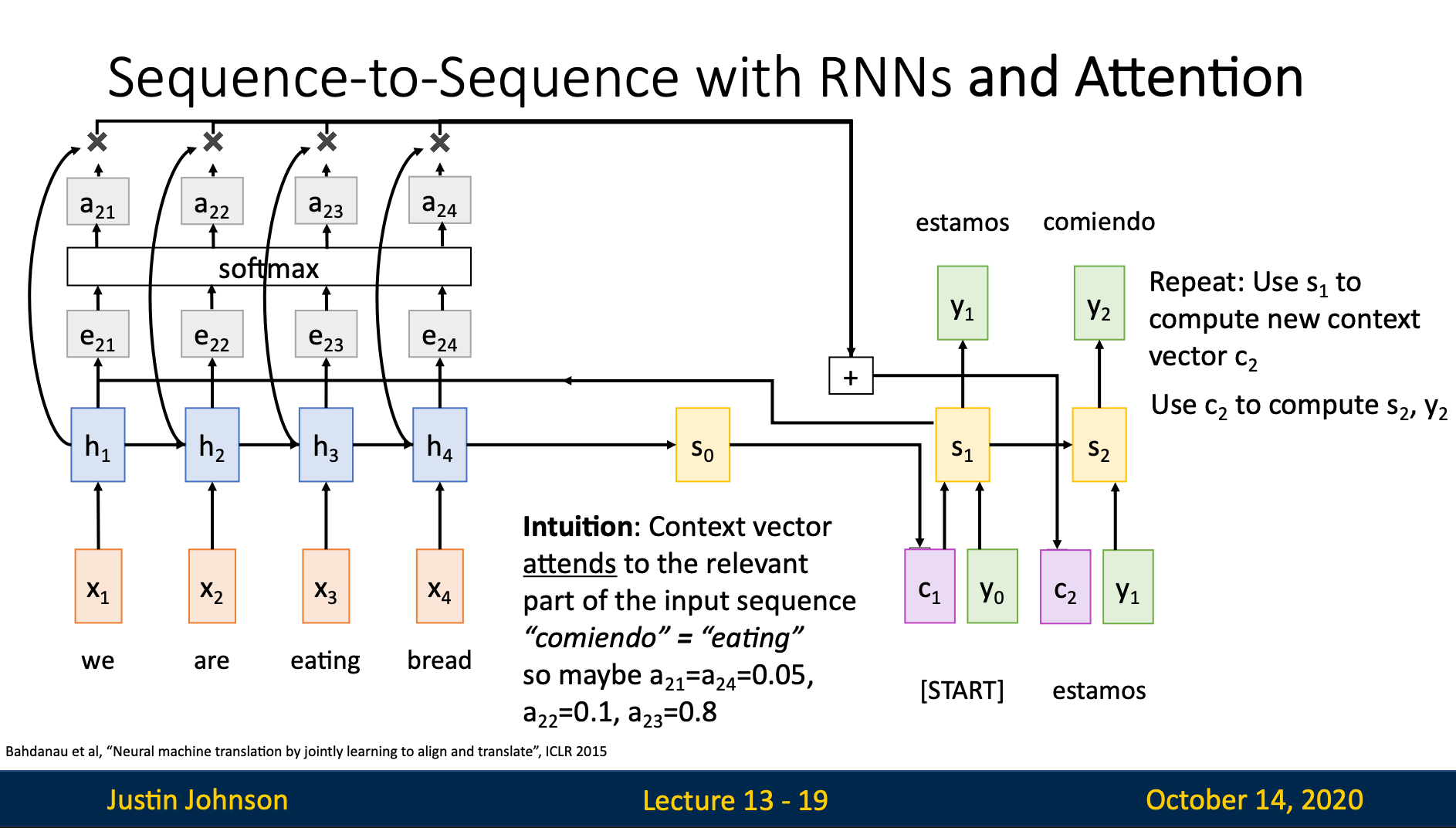
Intuition
Instead of using the same context vector for every time step, we let decoder at each time step decide itself which combination of hidden state does it think is more relevant to this time steps
Implementation
Use to assist finding hidden state relevant currently
For time step , memorizes all the information from the previous time steps, we can use it as a reference to decide which hidden states are more important in step
Steps
Step 1: Calculate Alignment Score
Alignment score is a scalar which represent how important the hidden state is to the time step
Computation of relies on
Step 2: Normalize Alignment Scores to get Attention Weights
Attention weights are the normalized probabilities derived from alignment scores that determine how much each encoder hidden state contributes to the current context vector
Step 3: Compute Context Vector
Step 4: Computer Decoder State
Example: English to French Translation
![]()
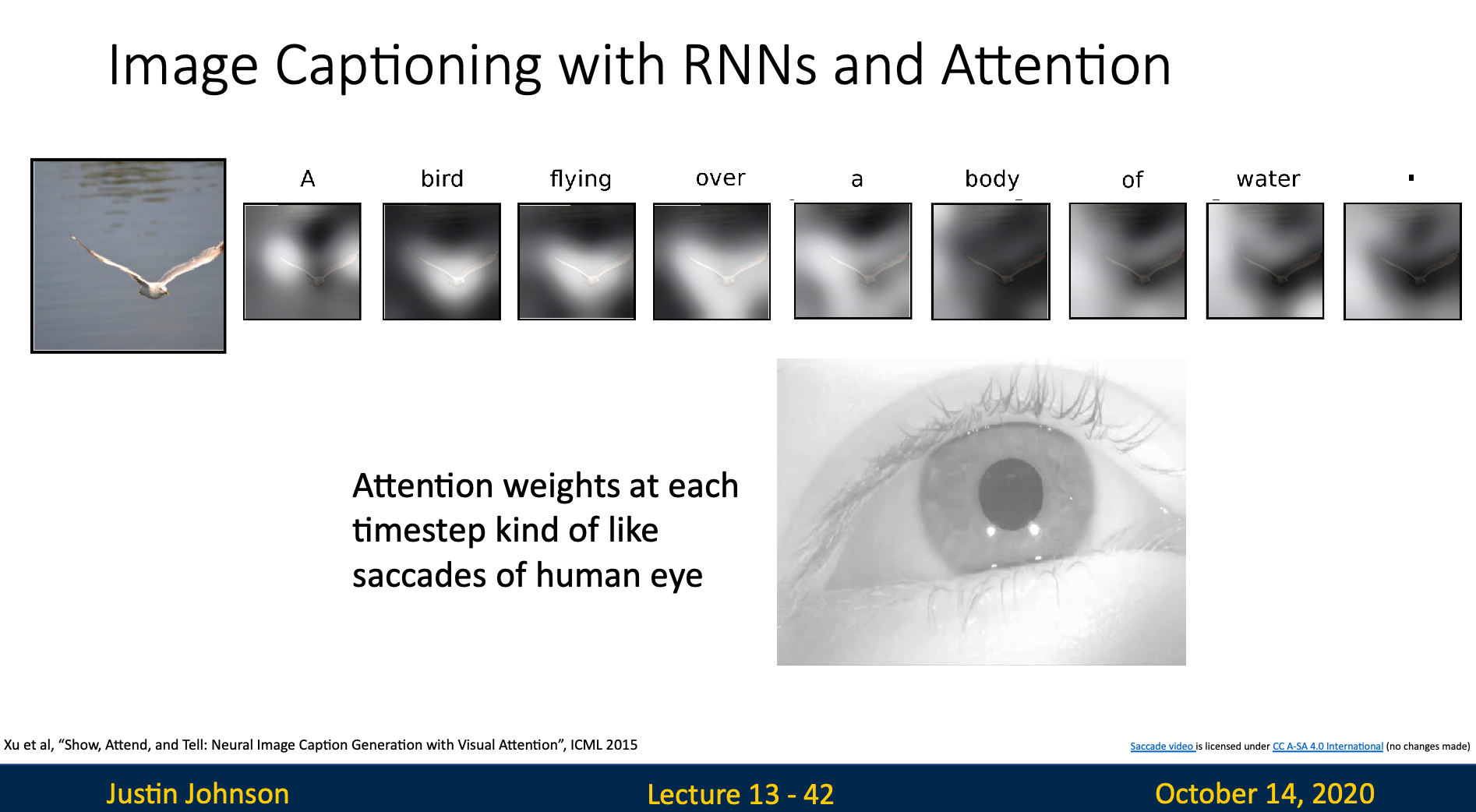
Image Captioning with RNNs and Attention
Implementation
very similar to basic attention implementation
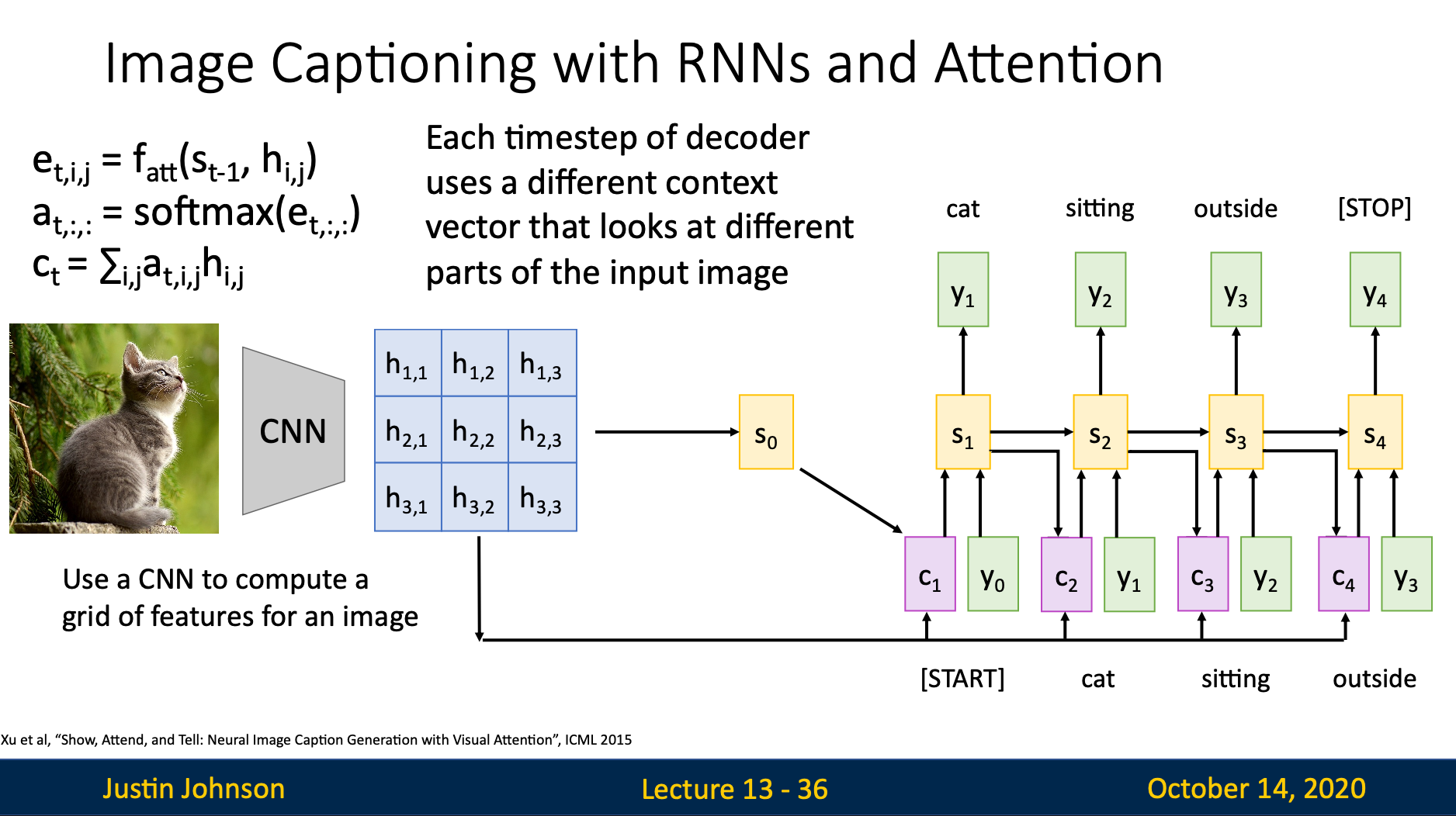
Intuition
The attention weights concentrated on the position which the current word (output) refers to
For example, when we generate the word “bird”, the weights will concentrate on the pixels of bird