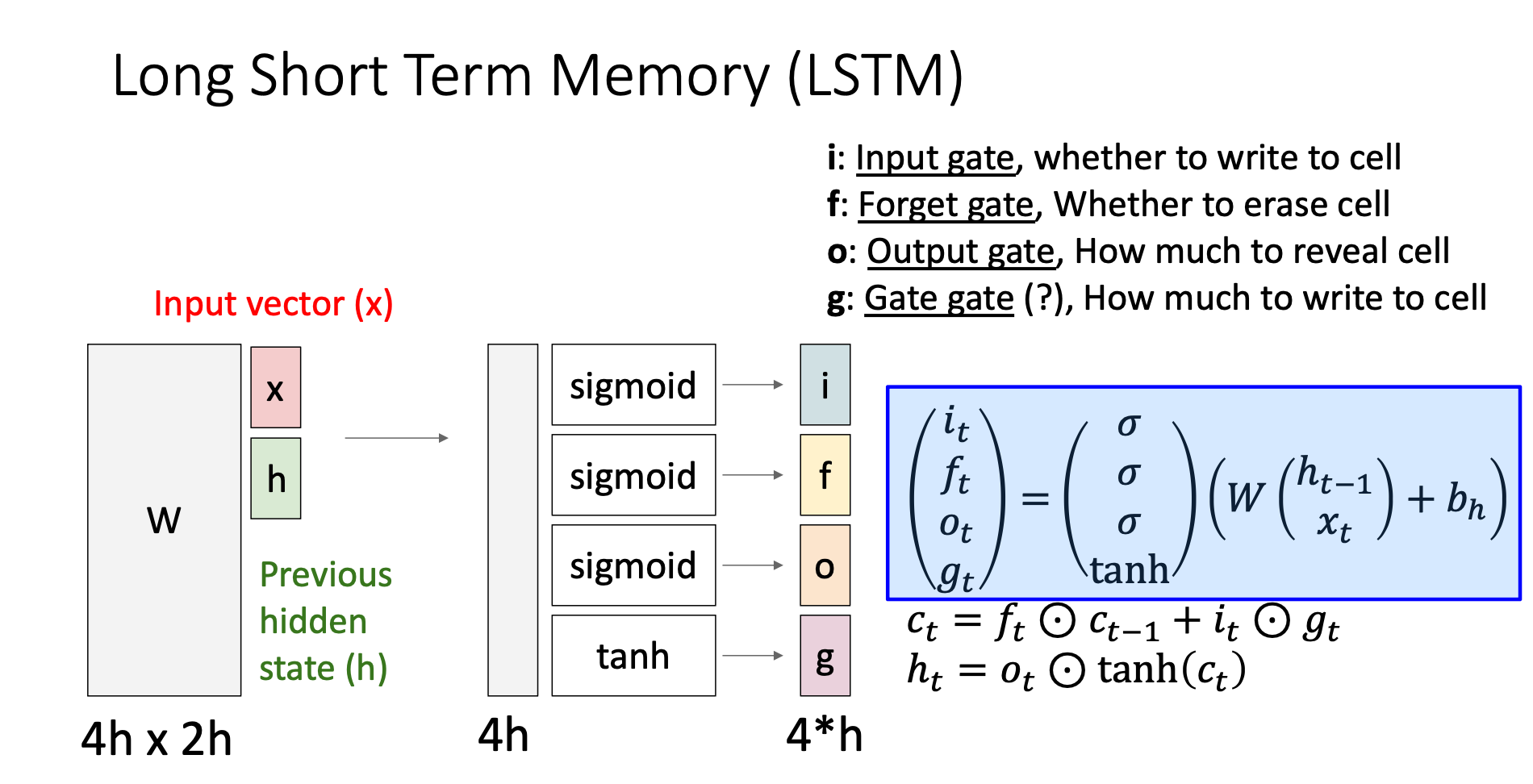
How’s LSTM different from Vanilla RNNs
1. Four States
In vanilla RNNs, the weight matrix multiplication directly gives us the hidden state. However, in LSTM, we cut the matrix into 4 parts then let them through different activation functions. These give us four output gates
2. Cell State
The cell state is like a “memory highway” which helps us resolve the backpropagation problem mentioned in Vanilla RNNs. We’ll discuss it later
Four States
Input Gate
It decides “how much” information we want to write to the cell state
Forget Gate
The forget gate tells us how much information from the previous sequence do I want to remember
Output Gate
If the output gate is small, then will be small, this can be understand as we reveals less information of cell state to the model, i.e., keep the cell state at this time step to be private
Gate Gate
It decides “what” do we want to write to the cell state at this time step
Cell State and Hidden State
Formula Explanation
: Add information from the previous input sequence to current cell state, decides how much do we want to add
: Add current input info to cell state, decides what to add, decides how much to add
: Reveal information to the public, decides how much to reveal
Uninterrupted Gradient Flow
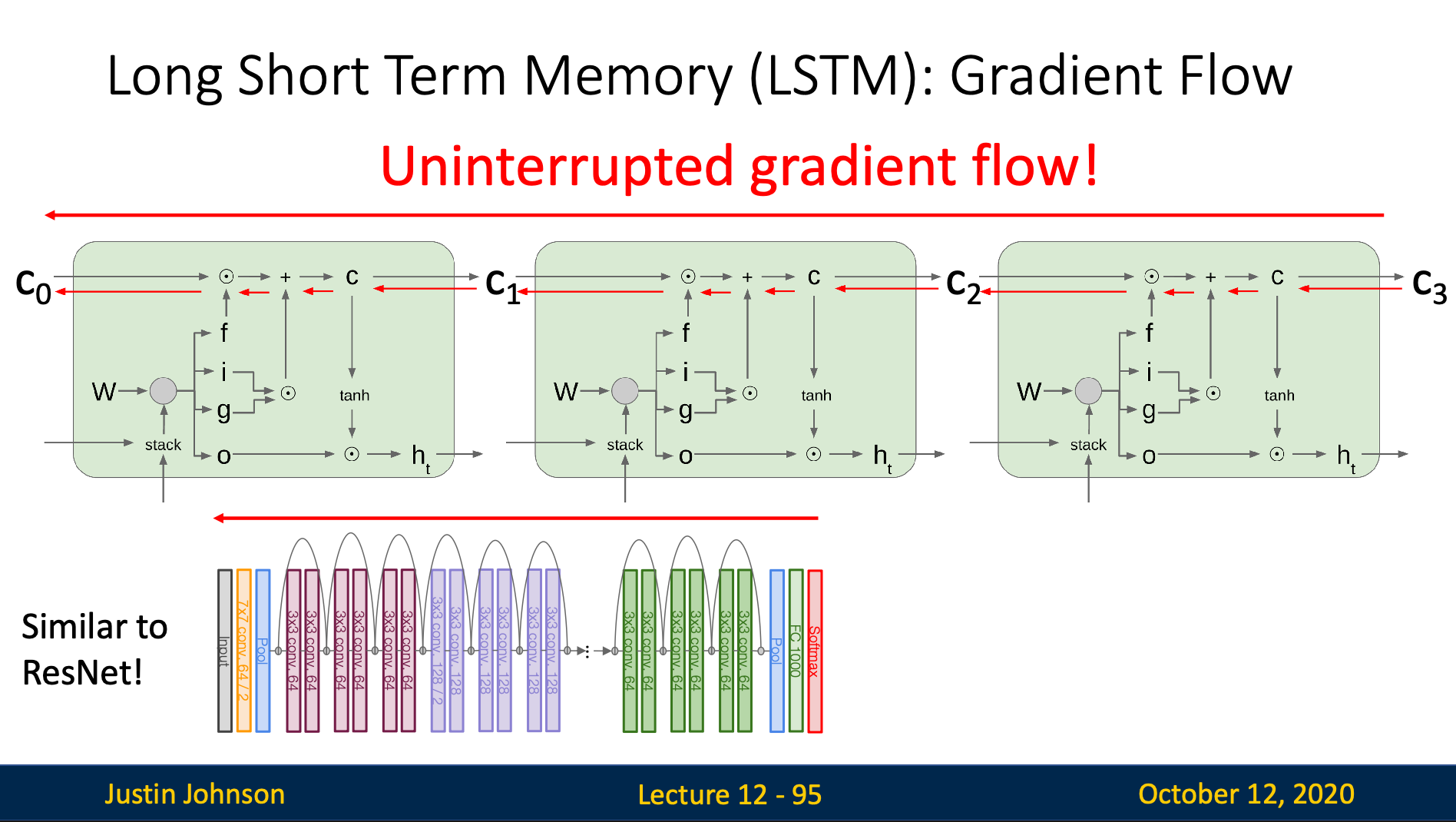
By observing the slide above, we can observe that the backward pass path only go through an addition and an element-wise matrix multiplication, which both don’t destroy information of the gradient flowing backward
We achieve this by making the gradient flow don’t go through any “nonlinearity” and “matrix multiplication”