Introduction
Introduction
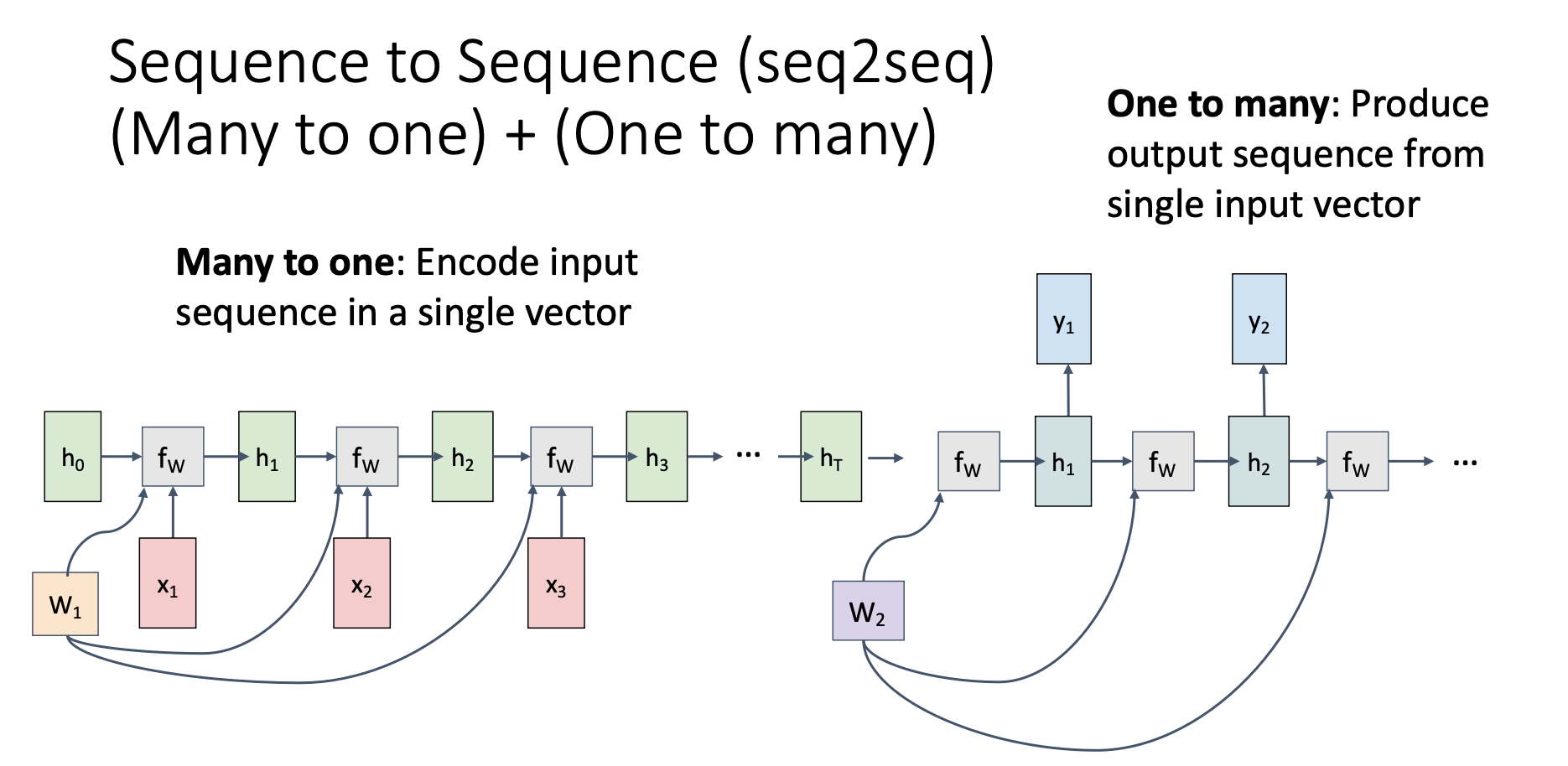
In sequence to sequence, we concatenate a “many to one” RNN and a “one to many” RNN together, using the final hidden state produced by the first RNN as the initial hidden state of second RNN
We call the first RNN the “encoder”, which suppress the input sequence into a fixed-size vector. On the other hand, we call the second RNN the “decoder”, which takes the context vector and produces output
Application
seq2seq enables us to have different numbers of input and output in RNNs
For example:
- Machine Translation: Different language use different number of words to describe the same thing
- Text Summarization: Convert long documents into short summaries