RNN Structure
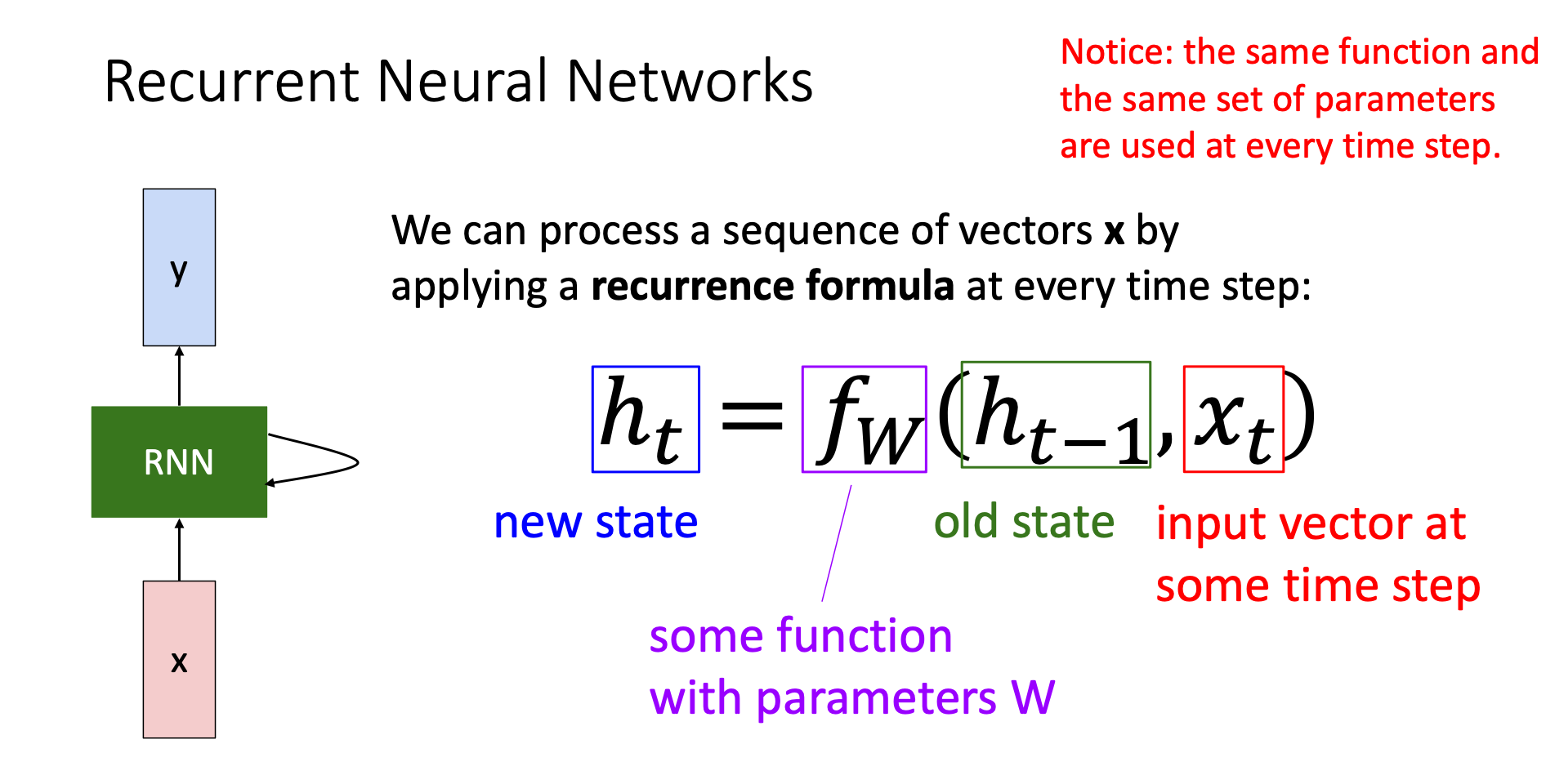
Parameters
| Variable | Description |
|---|---|
| The entire sequence of data you want to process (like a full sentence or time series) | |
| One piece of data at time step (like a single word in a sentence, or one data point in a time series) | |
| The RNN’s “memory” or internal state at the current moment - contains information from everything the network has seen so far | |
| The RNN’s “memory” from the previous moment - what the network remembered before seeing the current input | |
| The transformation function that combines the current input with previous memory to create new memory (this is where the learning happens) | |
| The learned weights/parameters that determine how to combine inputs and memory - these stay the same at every time step |
Key Concept
The main concept is that RNNs maintain a “memory” (hidden state) that memorize what the network see before the current input
Math Formula Intuition
- What the network see: current input
- What they remembered before: previous state
- Combine current input with memory to create new state: with weight
Every time step shares the same weight matrix , i.e., every time we use we are using the same weight matrix
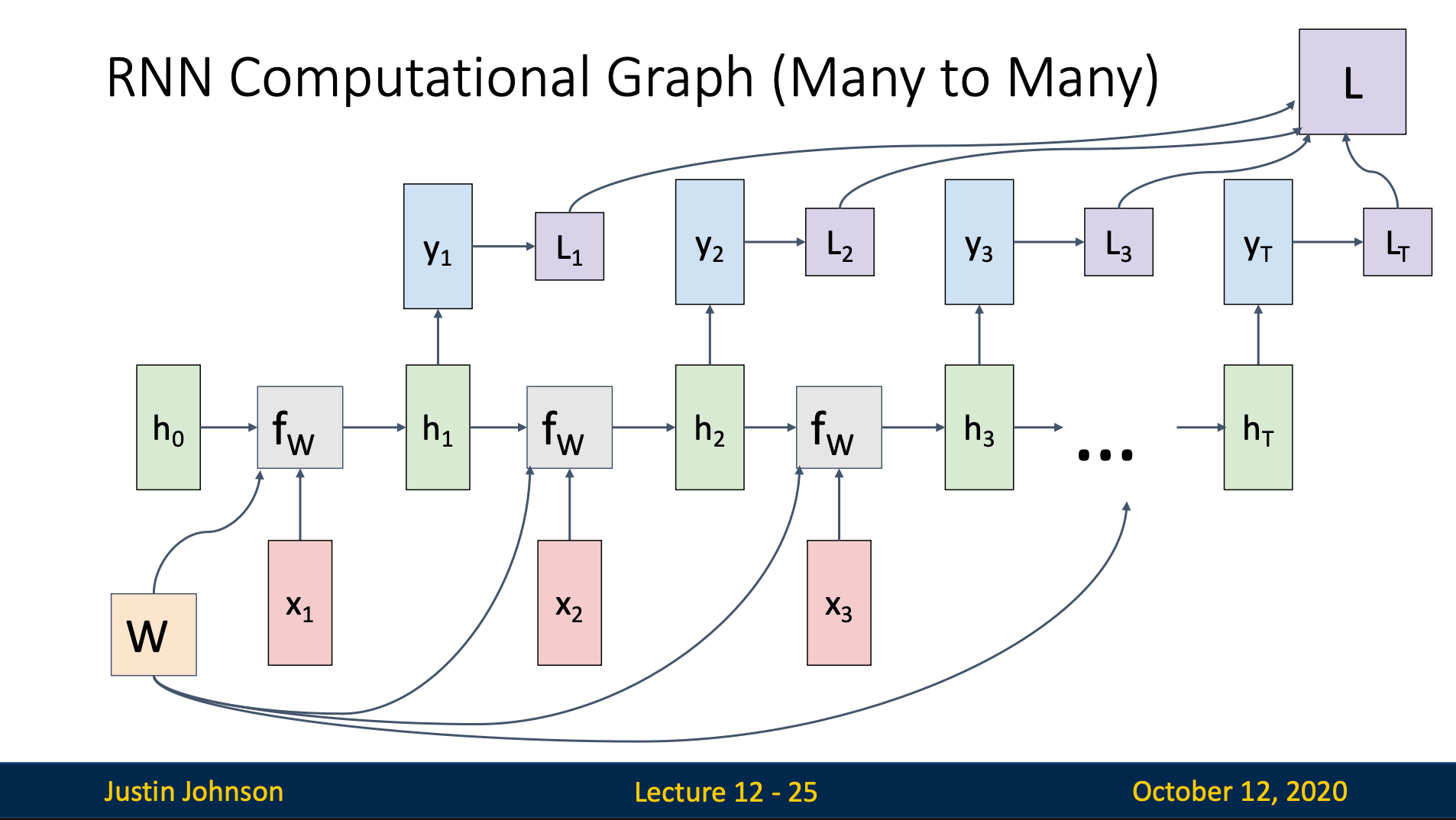
RNN Computational Graph
Backpropagation
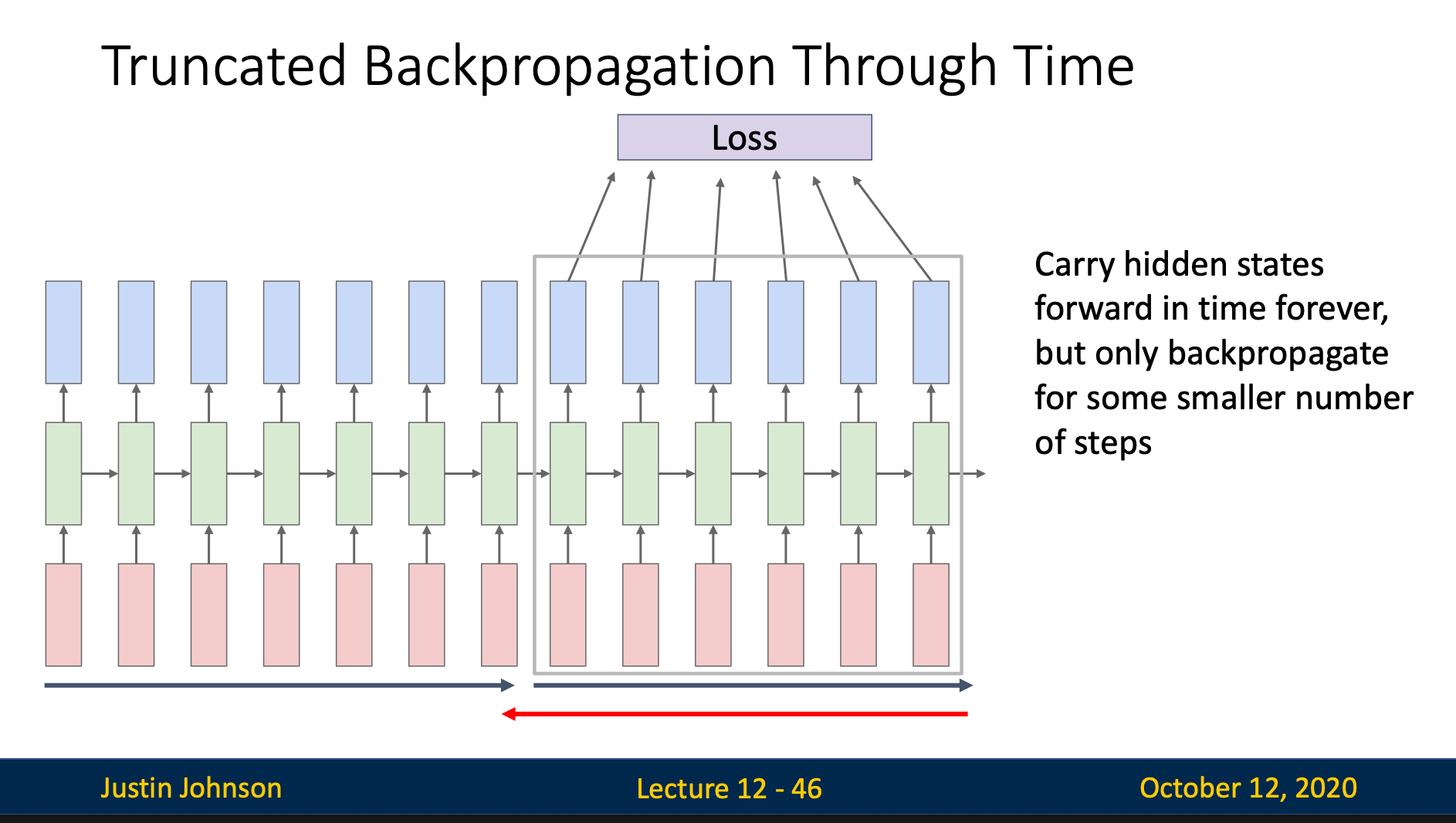
Problem
When we want to compute the gradient of loss, we need to remember the derivative of every steps, which will take a lot of memory when having long sequences
Solution: Truncated Backpropagation
We’ll divide the long sequence into some numbers of chunks, then run the forward pass and backward pass through chunks instead of whole sequence. This way, we only need to remember the derivatives in the chunk, and can forget it once we leave the chunk