Steps
Step 1: Check initial loss
Depends on the way we initialize the parameters, we expect the loss come in a certain range. We can thus check if the initial loss is reasonable before further training
For example, in lecture 3, we expect SVM loss with random weight initialization to have as initial loss, where is the number of classes
Step 2: Overfit a small sample
Strategy
This is the debugging step: If our model can’t overfit a tiny sample, something fundamentally broken
We’ll try to train 100% training accuracy on a small sample of training data (~5-10 minibatches); experiment with architecture, LR, weight initialization till things works
Guideline
Loss not going down:
- LR too low
- bad initialization
Loss explodes to Inf or NaN:
- LR too high
- bad initialization
or it may be bug in your code
Turn off regularization here
Step 3: Find LR that makes loss go down
Now, use the full training data instead of small samples. We want to find LR that makes loss drops significantly within ~100 iterations
This is also a debugging step, which confirm our architecture determined in step 2 works fine in large dataset
Good learning rate to try: 1e-1, 1e-2, 1e-3, 1e-4
Step 4: Coarse grid, train for ~1-5 epochs
Choose some value of LR and weight decay around what worked from Step 3, train a few models for ~1-5 epochs
Good weight decay to try: 1e-4, 1e-5, 0
Step 5: Refine grid, train longer
Pick best models from Step 4, train them for longer (~10-20 epochs) without learning rate decay
Step 6: Look at learning curves
We want to look at learning curves, utilizing the info given by the training process, adjust the model, then back to Step 5
Common Problem Detection
Learning Curves
Bad initialization
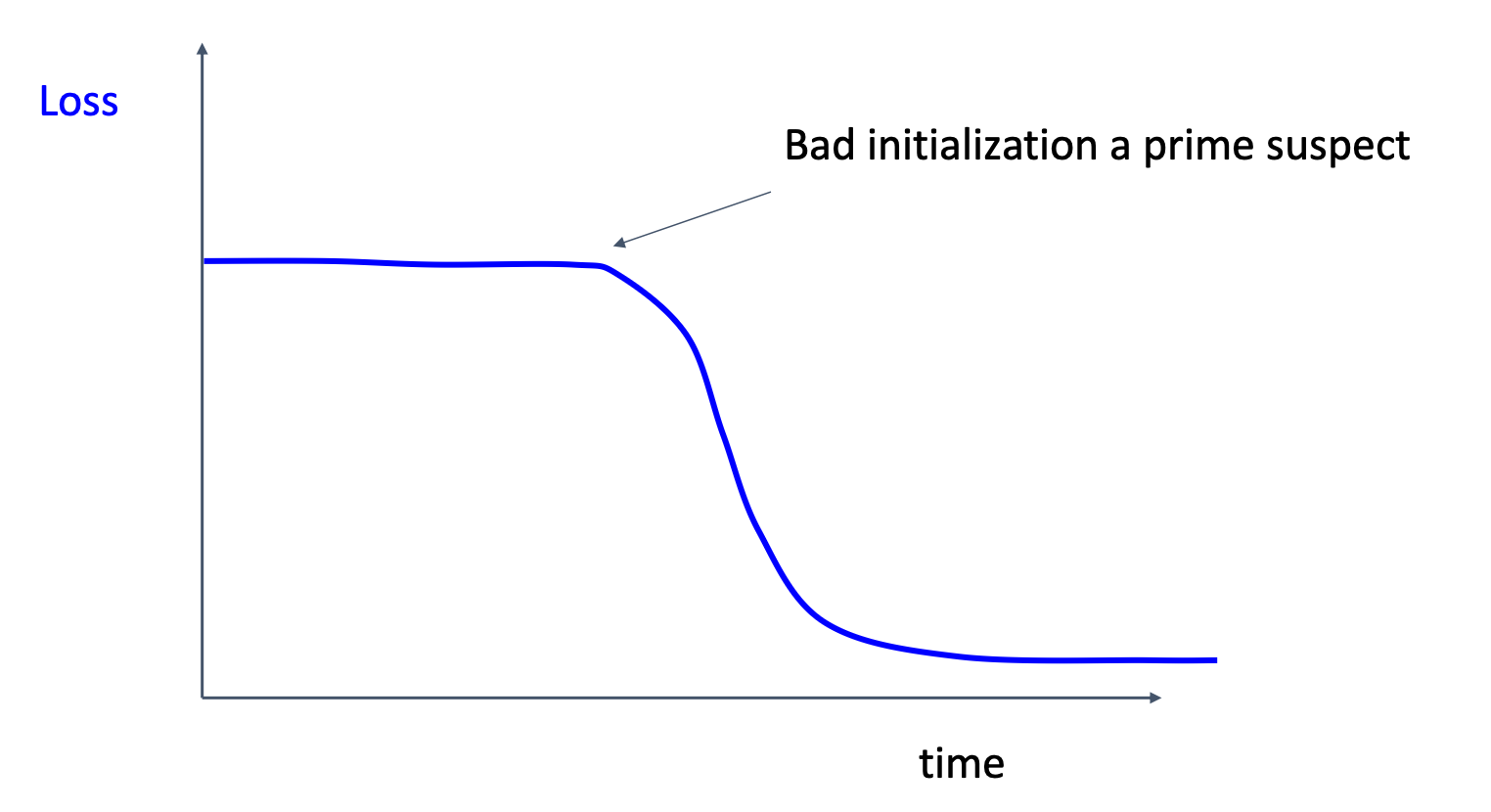 This may happen because we initialize the weights near regions where gradients are zero
This may happen because we initialize the weights near regions where gradients are zero
Loss plateaus
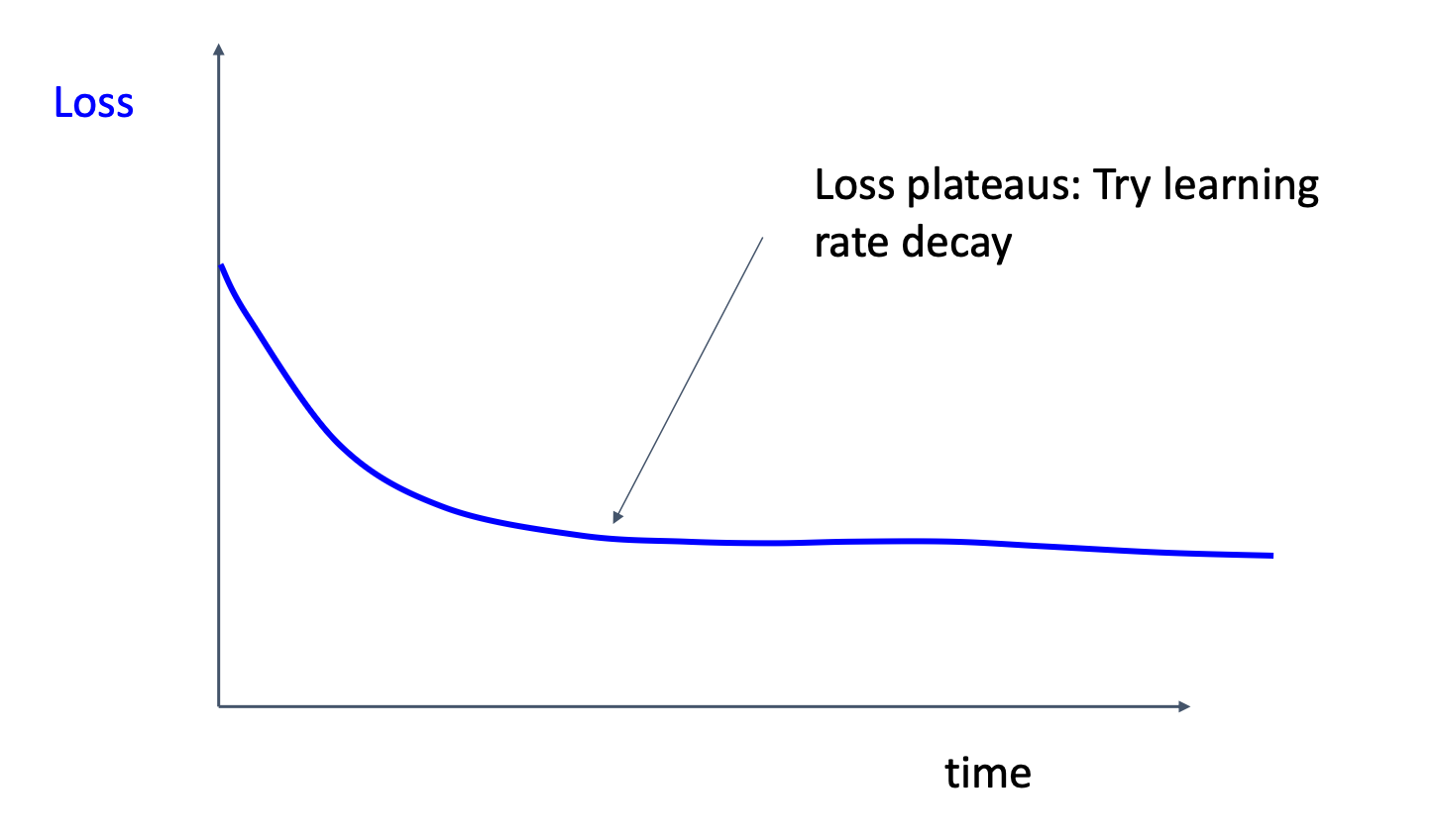 This situation may tells us that the model overshoot the minimum repeatedly, thus we may want to apply learning rate decay
This situation may tells us that the model overshoot the minimum repeatedly, thus we may want to apply learning rate decay
Learning rate step decay
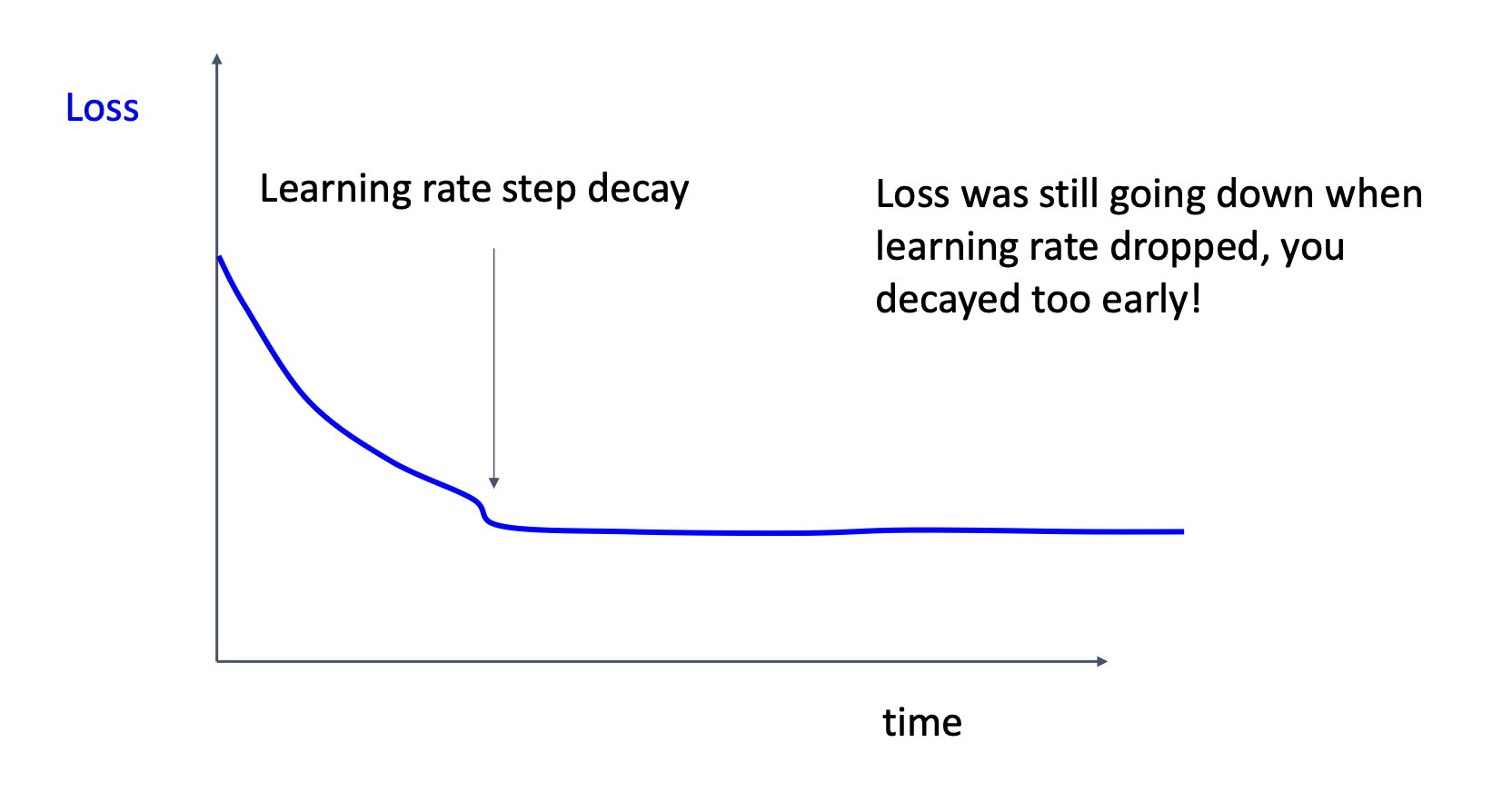 This suggests that we apply learning rate decay too early
This suggests that we apply learning rate decay too early
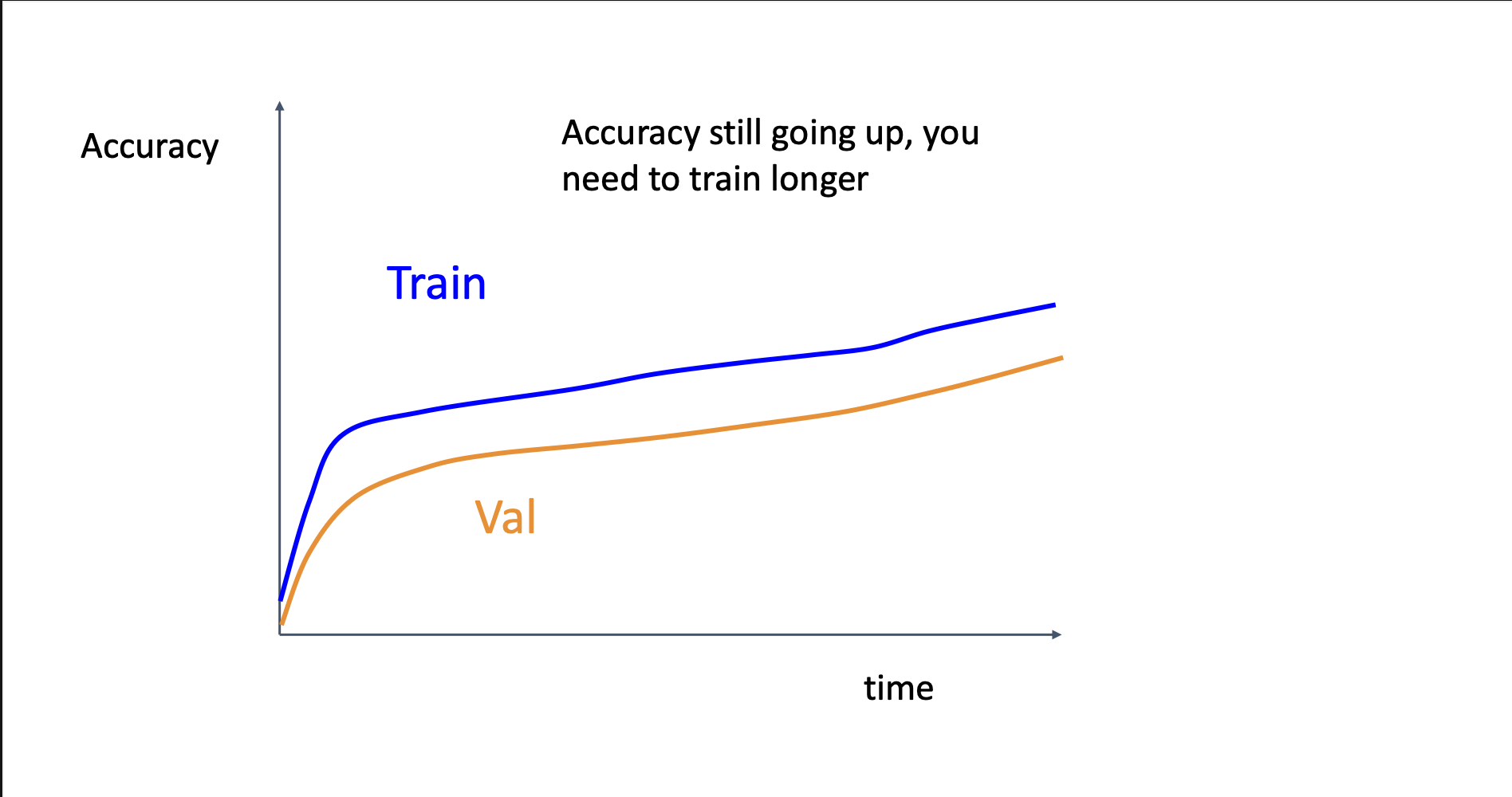
Accuracy Curve
Good curve, but need longer training
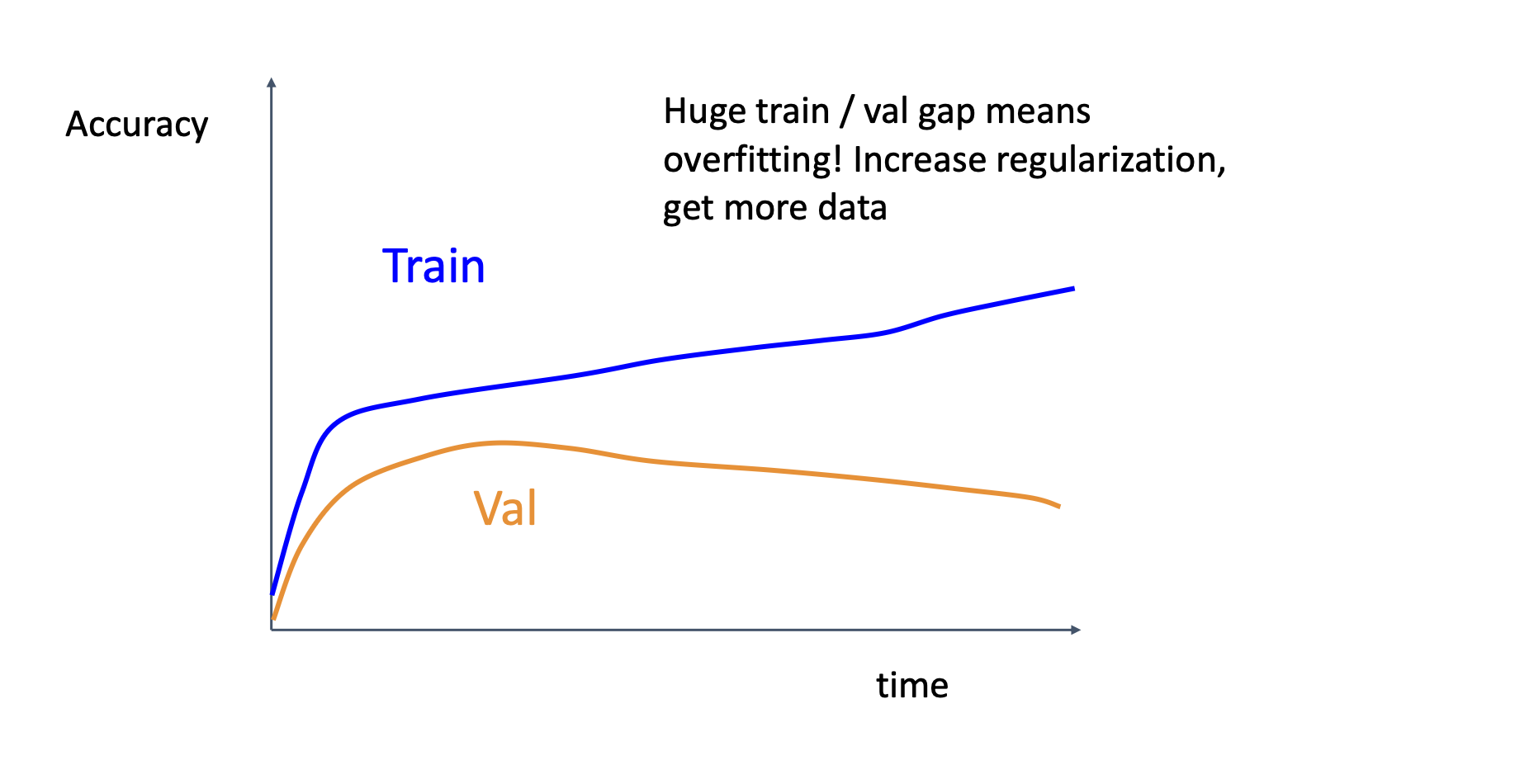
Overfitting, you may want more data or increase regularization
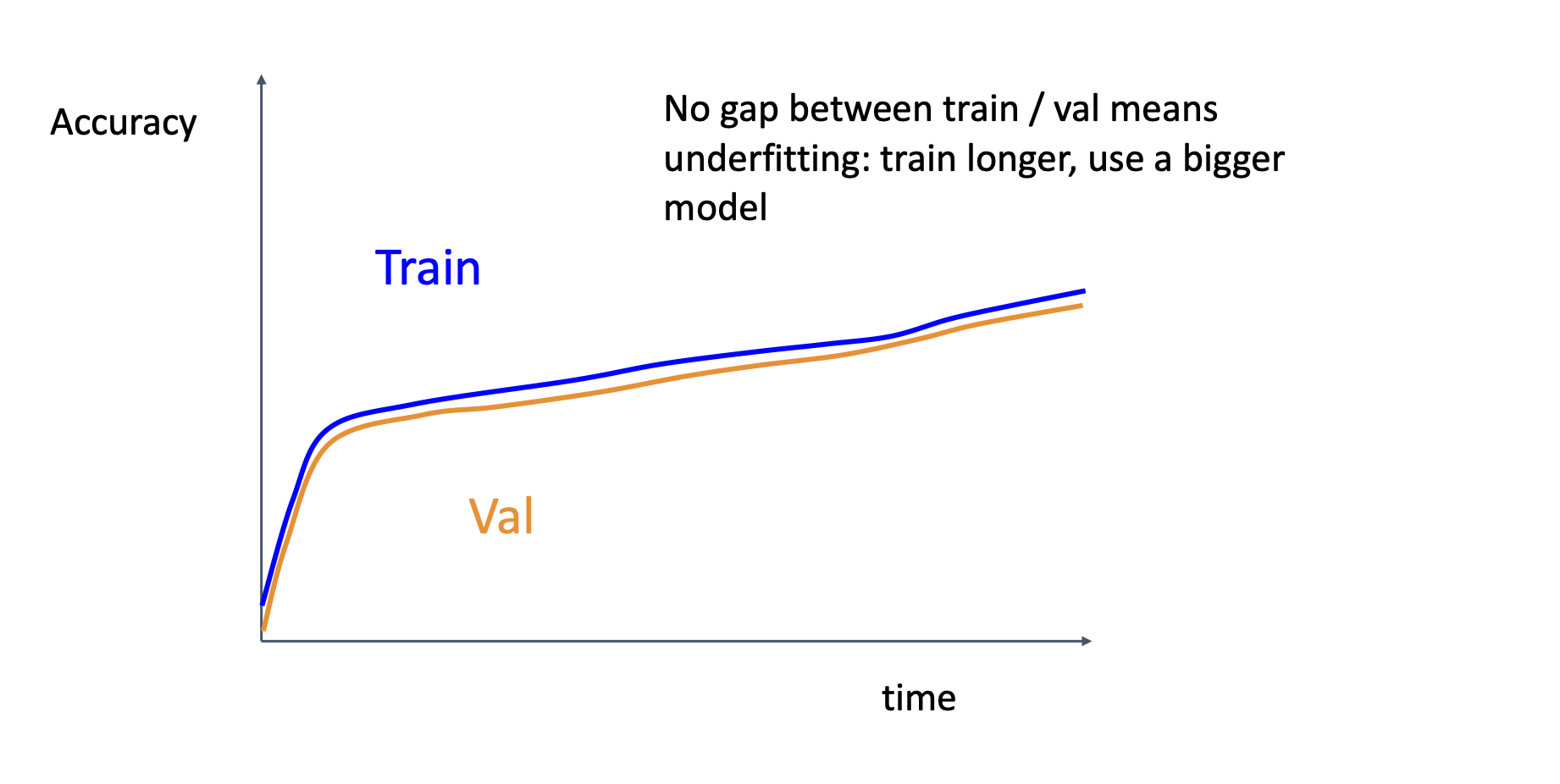
Underfitting, you may want to train longer or use a bigger model
Weight Update / Weight Magnitude
We want the ratio given below to be around 0.001