Why We Need to Discuss Weight Initialization?
To answer this question, we can see what if we set all the weights () and biases () to 0
Symmetry Breaking
Symmetry breaking refers to the process of ensuring that neurons in the same layer learn different features during training
When we set weights and biases to 0:
Forward Pass
Every neurons in the same layer receives the same input and produces identical outputs. When and , then the outputs are also 0
Backward Pass
- The loss gradient with respect of each hidden neuron’s output is identical
- Each hidden neuron receives the same gradient
- Therefore, all weights updates are identical
We'll still encounter this problem if we set all weights to the same values
Initialize with Small Random Numbers
What do we do?
We initialize the weights with small random numbers in Gaussian distribution with zero mean, i.e., W = 0.01 * np.random.randn(Din, Dout)
What might go wrong?
Shallow networks work fine, but deeper networks face initialization problems.
Weight too small (W = 0.01)
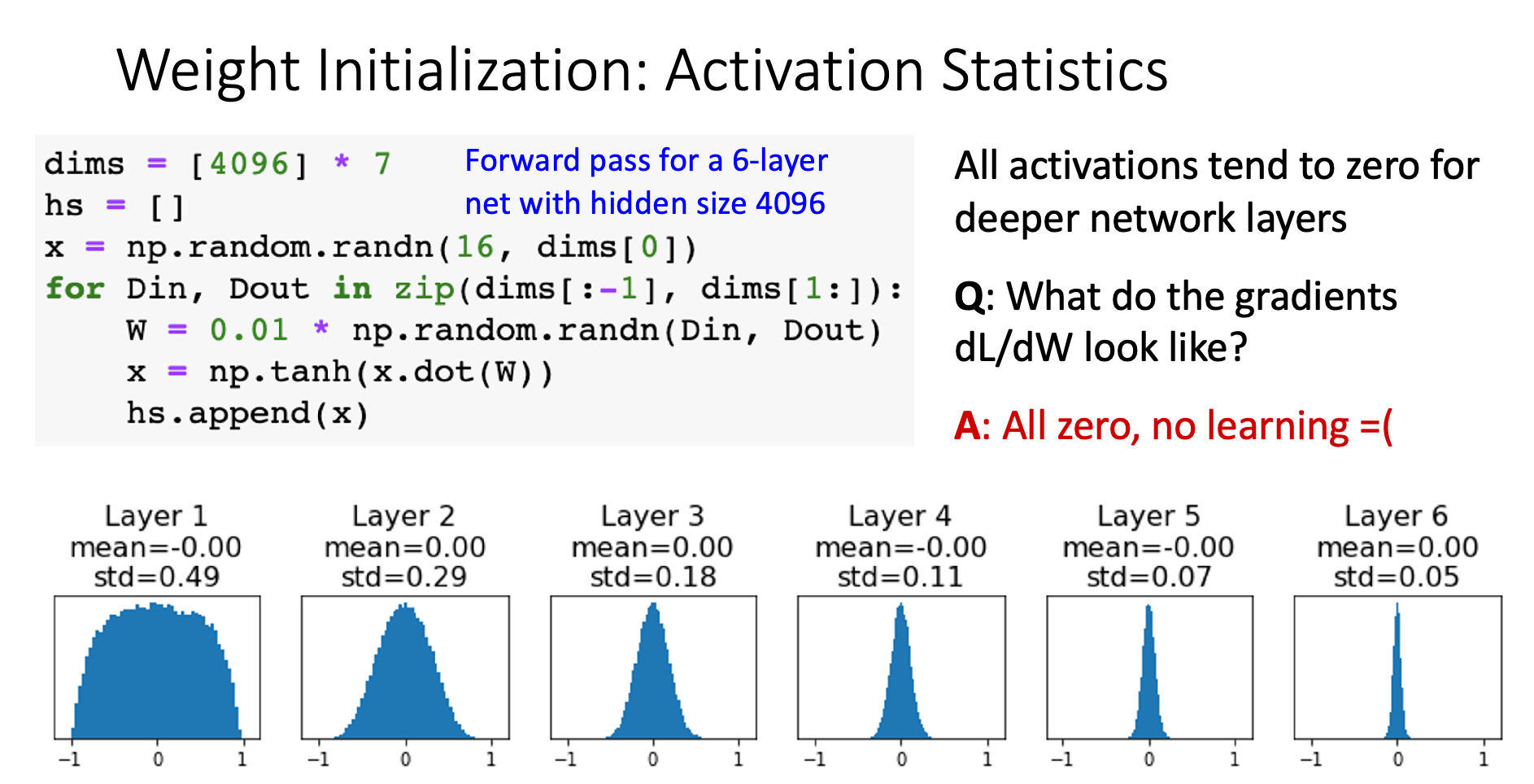
Problem chain: Weight small → Layer output small → Activations cluster near 0 → Next layer input small → Repeat…
Why no learning: Local gradient = (the input) Since x → 0, gradients → 0, so weight updates → 0
Weight too big (W = 0.05)
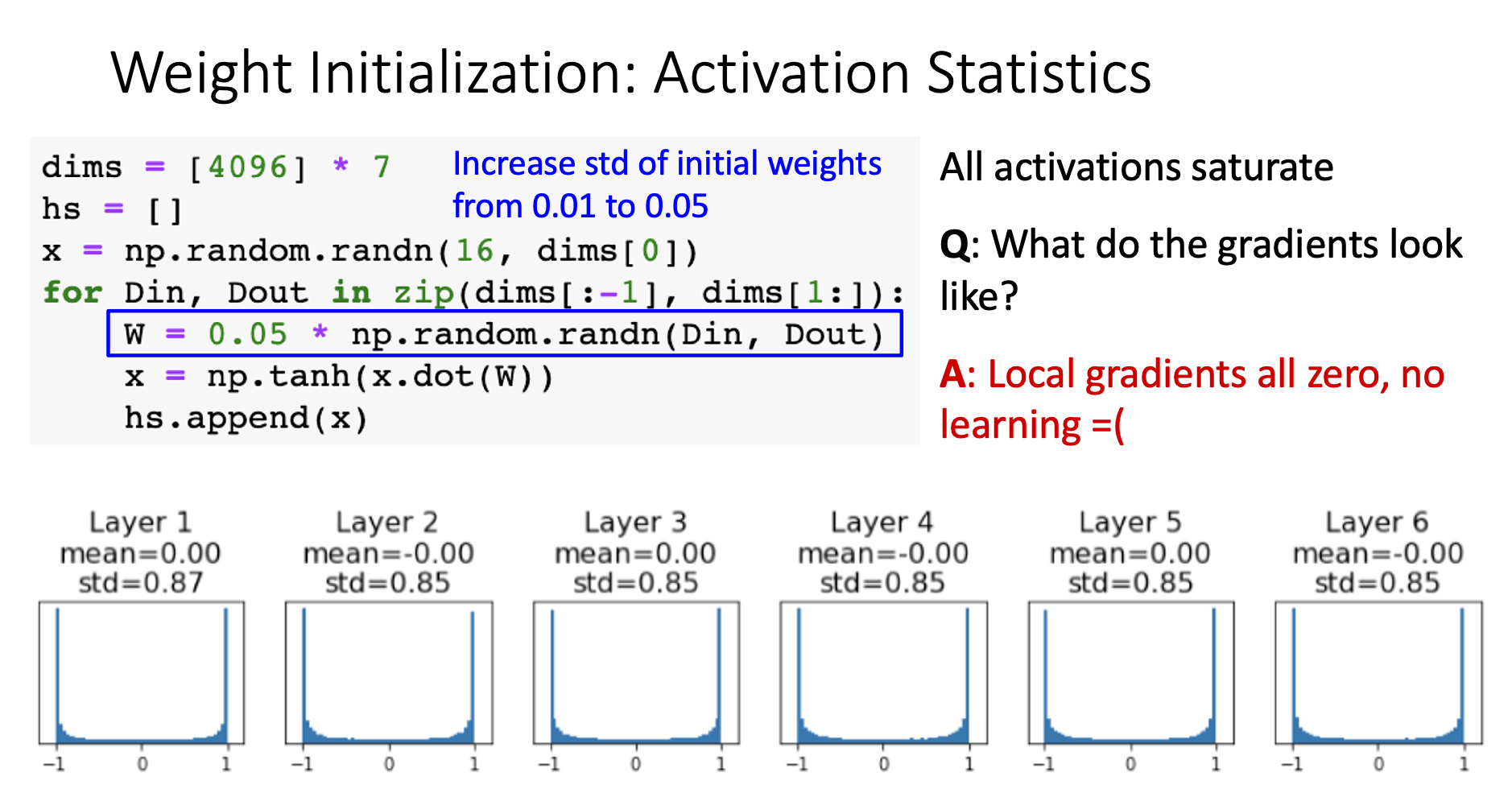
Problem chain: Weight large → Layer output large → Activations saturate at ±1 → Next layer input large → Repeat…
Why no learning: When tanh input is large, (saturated region) Local gradients → 0, so weight updates → 0
Key insight: Both extremes kill gradients - either through vanishing activations or saturated derivatives.
Xavier Initialization
Core Concept
The core concept of Xavier Initialization is making “variance of output = variance of input”
This concept only works for zero-centered activation
Method
We initialize weights with W = np.random.randn(Din, Dout) / np.sqrt(Din). This way of initialization will make activations work just fine
Derivation
Now, we can derive variance of
By the above equations we can tell **if then
ReLU Weight Initialization (Kaiming / MSRA Initialization)
Xavier initialization makes ReLU activations collapse to 0 because ReLU isn’t zero-centered
We can use Kaiming / MSRA initialization to correct it. This initialization adjust to
Residual Networks Weight Initialization
Problem: If we initialize residual network with MSRA: then . However, this makes , meaning variance grow with each residual block. This might cause variance explosion in deeper network
Solution: We initialize the first conv with MSRA, and the second conv to zero. Then